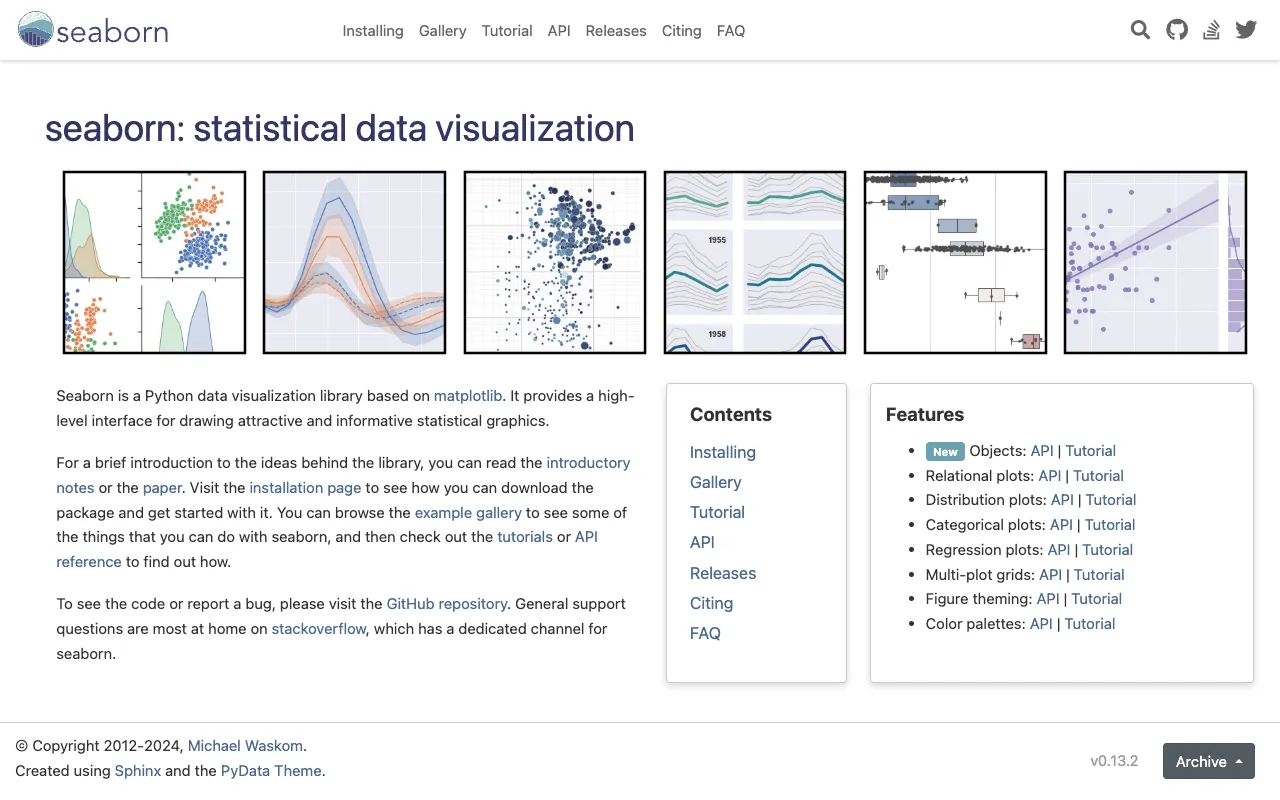
Seaborn – Die beste Python-Bibliothek für statistische Datenvisualisierung
Seaborn ist eine leistungsstarke, Open-Source-Python-Bibliothek, die speziell für die statistische Datenvisualisierung entwickelt wurde. Aufbauend auf Matplotlib bietet Seaborn eine High-Level-deklarative Schnittstelle, die es Data Scientists, Analysten und Forschern ermöglicht, mit minimalem Code ansprechende, informative und publikationsreife Diagramme zu erstellen. Es vereinfacht komplexe Visualisierungsaufgaben, bietet elegante Standardstile und integriert sich nahtlos mit pandas DataFrames, was es zur ersten Wahl für explorative Datenanalyse (EDA) und effektive Datenkommunikation macht.
Was ist die Seaborn-Python-Bibliothek?
Seaborn ist eine spezialisierte Python-Visualisierungsbibliothek mit Fokus auf statistische Grafiken. Im Gegensatz zu universellen Plotting-Bibliotheken ist Seaborn für Data-Science-Workflows konzipiert. Es versteht die Struktur Ihrer Daten, die oft in pandas DataFrames gespeichert sind, und bietet Funktionen, die Datenvariablen automatisch visuellen Elementen (wie Farbe, Farbton und Stil) zuordnen. Sein Hauptzweck ist es, die Visualisierung komplexer Datensätze und die Aufdeckung zugrunde liegender Muster, Verteilungen und Beziehungen zu vereinfachen. Es ist das Werkzeug der Wahl, wenn Sie über grundlegende Diagramme hinaus zu anspruchsvollen Visualisierungen wie Violin-Plots, Pair-Plots, gemeinsamen Verteilungen und Regressionsmodellen mit integrierter statistischer Schätzung gelangen möchten.
Wichtige Funktionen von Seaborn für Data Science
High-Level, deklarative API
Die größte Stärke von Seaborn ist seine Einfachheit. Mit nur ein oder zwei Codezeilen können Sie komplexe Visualisierungen erstellen, die viele Zeilen ausführlichen Matplotlib-Codes erfordern würden. Sie deklarieren, was Sie plotten möchten (z. B. eine Beziehung zwischen zwei Variablen, unterteilt nach einer dritten), und Seaborn übernimmt automatisch die komplexe Plotting-Logik, statistische Aggregation und ästhetische Gestaltung.
Integrierte statistische Plotting-Funktionen
Seaborn bietet Funktionen, die auf statistische Analysen zugeschnitten sind. Dazu gehören `lmplot()` und `regplot()` zur Visualisierung linearer Beziehungen mit Konfidenzintervallen, `distplot()`/`histplot()`/`kdeplot()` zur Untersuchung univariater und bivariater Verteilungen und `violinplot()`/`boxplot()` zum Vergleich von Verteilungen über Kategorien hinweg. Es integriert statistische Schätzungen nahtlos in den Visualisierungsprozess.
Schöne Standard-Themen und Stile
Seaborn bietet mehrere anspruchsvolle integrierte Themen (wie `darkgrid`, `whitegrid`, `dark`, `white` und `ticks`) und ein umfangreiches, kuratiertes Farbschema-System (`color_palette()`). Diese Standards sind ästhetisch ansprechend und für die Bildschirmanalyse sowie die akademische Veröffentlichung hochgradig lesbar gestaltet, wodurch Sie Stunden manueller Stilanpassungen sparen.
Pandas DataFrame-Integration
Seaborn ist für das pandas-Ökosystem entwickelt. Die meisten Funktionen akzeptieren Spaltennamen aus einem DataFrame direkt, was Ihren Code sauber und lesbar macht. Diese enge Integration ermöglicht eine intuitive Spezifikation von Datenvariablen, Gruppierungen und Faceting und optimiert den Workflow von der Datenmanipulation zur Visualisierung.
Multi-Plot-Grids (Faceting)
Die Objekte `FacetGrid` und `PairGrid` ermöglichen es Ihnen, komplexe Multi-Plot-Grids mühelos zu erstellen. Sie können Teilmengen Ihrer Daten zeilen- und spaltenübergreifend visualisieren (Faceting) oder eine Matrix von Beziehungen zwischen allen Variablen in einem Datensatz erstellen (Pair-Plots), was für die Exploration hochdimensionaler Daten unschätzbar wertvoll ist.
Für wen ist die Seaborn-Bibliothek geeignet?
Seaborn ist ein unverzichtbares Werkzeug für jeden, der in Python mit Daten arbeitet und Erkenntnisse visuell verstehen und kommunizieren muss. Sein Hauptpublikum sind **Data Scientists und Machine Learning Engineers** für explorative Datenanalyse (EDA) und Modelldiagnose. **Datenanalysten und Business-Intelligence-Experten** nutzen es, um klare, überzeugende Berichte und Dashboards zu erstellen. **Akademische Forscher und Studenten** in Bereichen wie Statistik, Sozialwissenschaften und Bioinformatik verlassen sich darauf, um publikationsreife Abbildungen zu generieren. **Python-Entwickler**, die datenzentrierte Anwendungen erstellen, integrieren Seaborn ebenfalls für seine leistungsstarken und einfachen Plotting-Fähigkeiten. Wenn Ihre Arbeit das Finden von Mustern in Daten beinhaltet und Sie pandas verwenden, ist Seaborn der natürliche nächste Schritt für Ihre Visualisierungsanforderungen.
Seaborn-Preise und Free Tier
Seaborn ist eine 100 % kostenlose und Open-Source-Bibliothek, die unter einer BSD-Lizenz vertrieben wird. Es gibt keine kostenpflichtige Stufe, kein Abonnement und keine Premium-Version. Sie können es für jeden Zweck, einschließlich kommerzieller und akademischer Projekte, völlig kostenlos nutzen. Sie können es kostenlos über pip (`pip install seaborn`) oder conda (`conda install seaborn`) installieren. Seine Entwicklung wird von der Open-Source-Community unterstützt, was sicherstellt, dass es ein leistungsstarkes, zugängliches Werkzeug für alle Datenprofis bleibt.
Häufige Anwendungsfälle
- Explorative Datenanalyse (EDA) für Machine-Learning-Projekte
- Erstellung von Korrelationsmatrizen und Pair-Plots zur Identifizierung von Variablenbeziehungen
- Visualisierung statistischer Modellanpassungen und Regressionsergebnisse mit Konfidenzintervallen
- Generierung publikationsreifer Abbildungen für akademische Arbeiten und Berichte
- Erstellung interner Dashboards und Daten-Geschichten für Business-Stakeholder
Hauptvorteile
- Reduzieren Sie den Code und die Zeit, die für die Erstellung komplexer statistischer Plots erforderlich sind, erheblich.
- Verbessern Sie die Klarheit und Wirkung Ihrer Datenkommunikation mit professionellen, lesbaren Visualisierungen.
- Beschleunigen Sie die Datenerkundungsphase jedes Projekts durch schnelle Visualisierung von Verteilungen und Beziehungen.
- Fördern Sie die Zusammenarbeit durch die Erstellung standardisierter, hochwertiger Grafiken, die leicht verständlich sind.
Vor- & Nachteile
Vorteile
- Äußerst intuitive und High-Level-API, die die Produktivität steigert.
- Erzeugt mit minimalem Aufwand schöne, publikationsreife Grafiken.
- Tiefe Integration mit pandas für einen nahtlosen Data-Science-Workflow.
- Leistungsstarke integrierte statistische Plotting-Funktionen, die in Basis-Matplotlib nicht vorhanden sind.
- Völlig kostenlos und Open-Source mit einer freizügigen Lizenz.
Nachteile
- Als High-Level-Wrapper bietet es weniger Kontrolle über Low-Level-Anpassungen als Matplotlib für hochspezialisierte Plots.
- Einige fortgeschrittene oder nicht-statistische benutzerdefinierte Visualisierungen erfordern möglicherweise immer noch den Rückgriff auf Matplotlib-Befehle.
- Die Performance kann bei der Darstellung extrem großer Datensätze (Zehntausende von Punkten oder mehr) langsamer sein als bei Matplotlib.
Häufig gestellte Fragen
Ist Seaborn kostenlos nutzbar?
Ja, Seaborn ist völlig kostenlos und Open-Source. Es wird unter einer BSD-Lizenz vertrieben, was bedeutet, dass Sie es frei für private, kommerzielle und akademische Projekte ohne jegliche Kosten oder Lizenzgebühren nutzen können.
Was ist der Unterschied zwischen Seaborn und Matplotlib?
Matplotlib ist eine umfassende Low-Level-Plotting-Bibliothek, die Ihnen umfangreiche Kontrolle über jedes Detail einer Abbildung gibt. Seaborn ist eine High-Level-Schnittstelle, die auf Matplotlib aufbaut. Es vereinfacht die Erstellung komplexer statistischer Grafiken durch intelligentere Standardeinstellungen, integrierte statistische Funktionen und eine pandas-freundlichere API, während es Ihnen gleichzeitig ermöglicht, bei Bedarf Matplotlib für finale Anpassungen zu verwenden.
Muss ich Matplotlib kennen, um Seaborn zu verwenden?
Während Sie mit den grundlegenden Funktionen von Seaborn ohne tiefgehende Matplotlib-Kenntnisse beginnen können, ist ein grundlegendes Verständnis von Matplotlib sehr vorteilhaft. Da Seaborn-Objekte im Kern Matplotlib-Objekte sind, hilft die Kenntnis von Matplotlib bei der erweiterten Anpassung von Achsen, Beschriftungen und Abbildungseigenschaften und gibt Ihnen die volle Leistungsfähigkeit beider Bibliotheken an die Hand.
Ist Seaborn gut für Data Science und Machine Learning?
Absolut. Seaborn ist eine der meistempfohlenen Bibliotheken für die Phase der explorativen Datenanalyse (EDA) in Data-Science- und ML-Projekten. Seine Fähigkeit, Verteilungen, Korrelationen und Beziehungen zwischen Variablen schnell zu visualisieren, ist unschätzbar wertvoll, um Ihre Daten zu verstehen, Annahmen zu überprüfen und Erkenntnisse vor und nach der Modellerstellung zu kommunizieren.
Fazit
Für Data Scientists, Analysten und Forscher, die in Python arbeiten, ist Seaborn nicht nur eine Visualisierungsbibliothek – es ist ein Produktivitätsmultiplikator und eine wesentliche Komponente des modernen Data-Stacks. Es überbrückt meisterhaft die Lücke zwischen der rohen Leistungsfähigkeit von Matplotlib und dem Bedarf an schnellen, schönen und statistisch fundierten Grafiken. Indem Seaborn die Codekomplexität für fortgeschrittene Plots dramatisch reduziert, können Sie sich auf das konzentrieren, was am wichtigsten ist: das Verstehen Ihrer Daten. Wenn Ihre Arbeit die Erkundung von Mustern, das Erzählen von Geschichten mit Daten oder die Präsentation von Ergebnissen beinhaltet, ist die Integration von Seaborn in Ihren Workflow eine Entscheidung, die sich sofort in Klarheit, Effizienz und visueller Wirkung auszahlt.