arXiv – L'Archivio di Ricerca Gratuito Essenziale per Ricercatori di IA
arXiv è il pilastro della scoperta accademica moderna per ricercatori di IA, ingegneri del machine learning e informatici. Questo pionieristico repository ad accesso aperto fornisce accesso istantaneo e gratuito a oltre 2 milioni di preprint accademici—articoli di ricerca pubblicati prima della revisione paritaria formale. Per professionisti e studenti all'avanguardia nell'intelligenza artificiale, elaborazione del linguaggio naturale e deep learning, arXiv non è solo uno strumento; è il canale principale per le ultime innovazioni, metodologie e progressi teorici, garantendo che tu non lavori mai con informazioni obsolete.
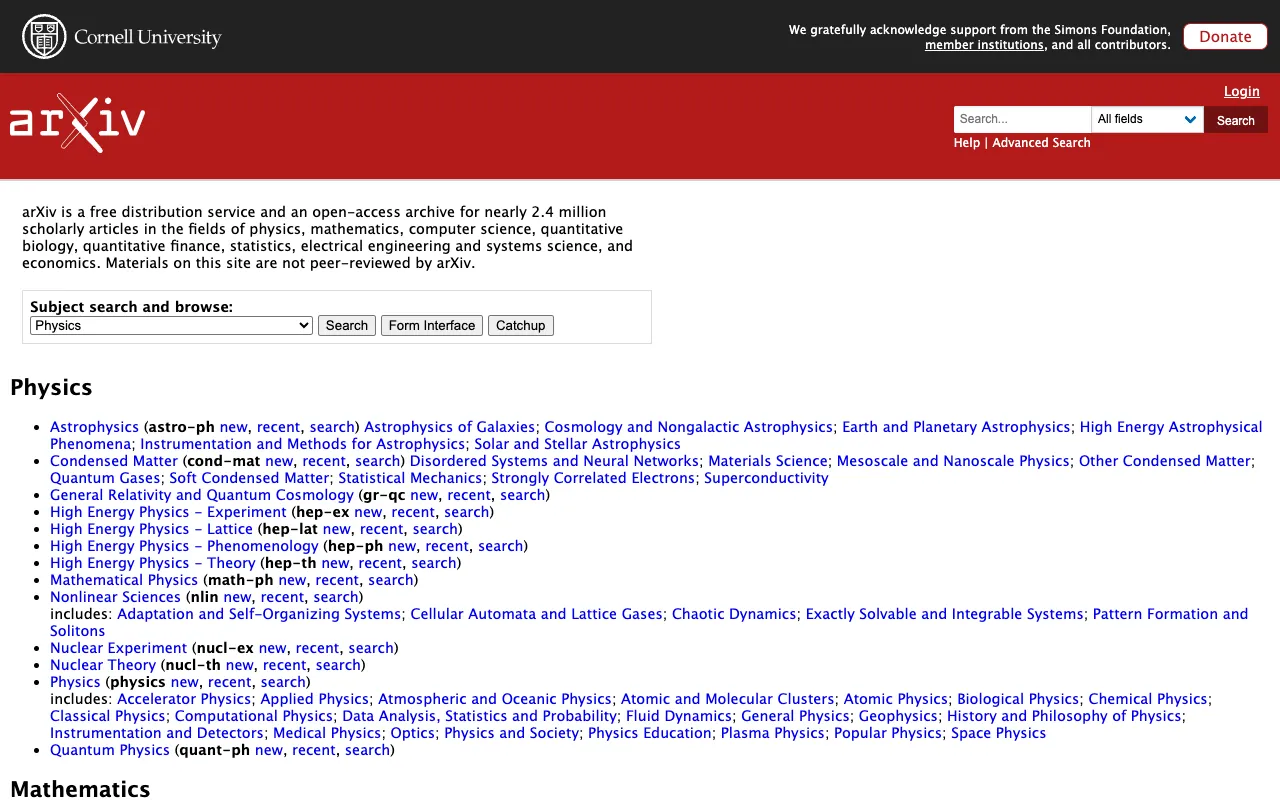
Cos'è arXiv?
arXiv è una biblioteca digitale e piattaforma di distribuzione non-profit e supportata dalla comunità per la ricerca scientifica. Fondato nel 1991, ha rivoluzionato l'editoria accademica permettendo ai ricercatori di condividere immediatamente i loro risultati come 'preprint'. Per la comunità di ricerca sull'IA, arXiv ospita articoli fondamentali in sottocampi come visione artificiale, apprendimento per rinforzo, reti neurali e grandi modelli linguistici (LLM) molto prima che appaiano su riviste o conferenze formali. Democratizza l'accesso alla ricerca di alto livello, accelerando l'innovazione e la collaborazione tra accademia e industria rimuovendo paywall e ritardi nella pubblicazione.
Caratteristiche Principali di arXiv per la Ricerca sull'IA
Repository Enorme e Curato di IA/ML
Accedi a un vasto database ricercabile, specificamente categorizzato per l'informatica (cs), inclusi sotto-categorie dedicate come cs.AI (Intelligenza Artificiale), cs.LG (Machine Learning), cs.CL (Calcolo e Linguaggio) e cs.CV (Visione Artificiale). Questa tassonomia strutturata rende efficiente e precisa la ricerca di studi rilevanti e all'avanguardia nella tua nicchia.
Accesso Aperto Istantaneo e Nessun Paywall
Ogni singolo articolo su arXiv è completamente gratuito da leggere e scaricare in formato PDF. Questo elimina la barriera finanziaria dei costosi abbonamenti a riviste, rendendo la ricerca innovativa sull'IA accessibile a ricercatori indipendenti, studenti, startup e istituzioni in tutto il mondo.
Velocità delle Preprint e della Ricerca
La tempistica dalla sottomissione alla pubblicazione su arXiv è spesso di soli uno o due giorni. Ciò significa che puoi accedere alle ultime scoperte di ricerca, inclusi risultati negativi e aggiornamenti incrementali, mesi prima del completamento della revisione paritaria tradizionale. Per campi in rapida evoluzione come l'IA, questa velocità è fondamentale per mantenere un vantaggio competitivo.
Ricerca, Navigazione e Alert Robusti
Una potente funzionalità di ricerca consente di filtrare per categoria, data, autore e titolo. Puoi impostare avvisi email per nuove submission in categorie specifiche o basati su ricerche per parole chiave, garantendo di essere automaticamente informato sugli articoli che corrispondono ai tuoi interessi di ricerca.
Rete di Citazioni e Cronologia delle Versioni
Traccia l'influenza di un articolo attraverso i dati di citazione e i collegamenti. arXiv mantiene una cronologia completa delle versioni per ogni submission, permettendoti di vedere come la ricerca si è evoluta, verificare correzioni e comprendere il processo di sviluppo dietro le principali innovazioni in IA.
Chi Dovrebbe Usare arXiv?
arXiv è indispensabile per chiunque operi alla frontiera della conoscenza sull'IA. Gli utenti principali includono scienziati e ingegneri della ricerca in IA sia in ambito accademico che aziendale, che necessitano degli ultimi algoritmi e modelli. Dottorandi e studenti laureati lo usano per revisioni della letteratura e ricerche per tesi. Professionisti e sviluppatori di machine learning vi fanno affidamento per implementare tecniche all'avanguardia. Giornalisti e analisti tecnologici lo monitorano per le tendenze. Anche appassionati curiosi e studenti autodidatti di IA beneficiano della sua filosofia di accesso aperto.
Prezzi e Piano Gratuito di arXiv
arXiv è ed è sempre stato completamente gratuito per tutti gli utenti. Non esiste un modello di prezzi, una quota di abbonamento o un piano a pagamento. Leggere, scaricare e cercare nell'intero archivio di milioni di articoli accademici non costa nulla. Il servizio è sostenuto da sovvenzioni, supporto istituzionale e donazioni, mantenendo la sua missione di fornire accesso aperto alla ricerca scientifica per la comunità globale.
Casi d'uso comuni
- Condurre una revisione della letteratura per una nuova tesi o progetto di ricerca sul machine learning
- Rimanere aggiornati sulle ultime innovazioni nelle architetture dei grandi modelli linguistici (LLM)
- Trovare dettagli implementativi e collegamenti a codice open-source per modelli di IA recenti
- Monitorare la produzione di ricerca e i nuovi articoli dei principali laboratori e autori di IA
- Scoprire preprint su etica, sicurezza e impatto sociale dell'IA prima della pubblicazione formale
Vantaggi principali
- Accelera la tua tempistica di ricerca fornendo accesso immediato alle scoperte più recenti, non alle notizie di ieri.
- Risparmia soldi significativi rispetto ai costosi abbonamenti a riviste accademiche o licenze di database.
- Migliora la qualità e la novità del tuo lavoro costruendo sulla ricerca allo stato dell'arte più attuale.
- Promuove una comunità di ricerca globale sull'IA più trasparente e collaborativa.
Pro e contro
Pro
- Completamente gratuito e ad accesso aperto senza limiti di utilizzo.
- Velocità impareggiabile per accedere alle ricerche più recenti (preprint).
- Archivio esteso e ben organizzato specificamente per l'IA e l'informatica.
- Essenziale per l'intelligence competitiva e per restare avanti nei campi dell'IA in rapida evoluzione.
- Interfaccia semplice e diretta focalizzata sulla scoperta dei contenuti.
Contro
- Gli articoli sono preprint e potrebbero non aver subito una revisione paritaria formale (richiede valutazione critica).
- L'enorme volume di submission giornaliere può essere travolgente senza un uso attento di filtri e avvisi.
- Manca alcune funzionalità analitiche avanzate presenti nei database accademici commerciali.
- La funzionalità di ricerca, sebbene robusta, potrebbe non essere raffinata come i motori di ricerca accademici a pagamento.
Domande frequenti
arXiv è gratuito?
Sì, arXiv è completamente gratuito. Non ci sono costi per leggere, cercare o scaricare nessuno degli oltre 2 milioni di articoli di ricerca nel suo archivio. Opera con un modello non-profit sostenuto da sovvenzioni e donazioni.
arXiv è utile per la ricerca sull'IA e il machine learning?
Assolutamente sì. arXiv è la fonte definitiva per le ultime preprint sull'intelligenza artificiale e il machine learning. Grandi innovazioni come le architetture Transformer, AlphaGo e gli articoli fondamentali sugli LLM sono stati pubblicati lì per primi. Le sue categorie cs.AI e cs.LG sono letture obbligatorie per qualsiasi serio ricercatore di IA.
Qual è la differenza tra una preprint di arXiv e un articolo pubblicato?
Una preprint di arXiv è una versione di un articolo di ricerca condivisa pubblicamente prima che subisca una revisione paritaria formale da parte di una rivista o conferenza. La versione finale pubblicata potrebbe avere revisioni minori. Per velocità e apertura, la comunità dell'IA fa molto affidamento e cita la versione arXiv.
Come trovo articoli di IA rilevanti su arXiv?
Usa la barra di ricerca con parole chiave specifiche o nomi di autori. Per la navigazione, vai alla categoria 'Computer Science' e poi seleziona sotto-categorie rilevanti come cs.AI (Intelligenza Artificiale) o cs.LG (Machine Learning). Impostare avvisi email per le tue categorie scelte è il modo più efficace per rimanere aggiornati.
Conclusione
Per qualsiasi professionista o studente impegnato nella ricerca sull'intelligenza artificiale, arXiv non è semplicemente uno strumento utile—è un'infrastruttura indispensabile del campo. Il suo impegno per l'accesso istantaneo, gratuito e aperto ha plasmato fondamentalmente il modo in cui la conoscenza dell'IA viene creata e diffusa. Sebbene richieda agli utenti di esercitare un giudizio critico a causa della sua natura di preprint, il beneficio di accedere alla frontiera grezza dell'innovazione supera di gran lunga questa considerazione. Per scoprire la prossima grande idea nel machine learning, comprendere una nuova architettura di rete neurale o semplicemente rimanere aggiornati in una disciplina in rapida evoluzione, arXiv rimane il punto di partenza inequivocabile e la destinazione quotidiana.