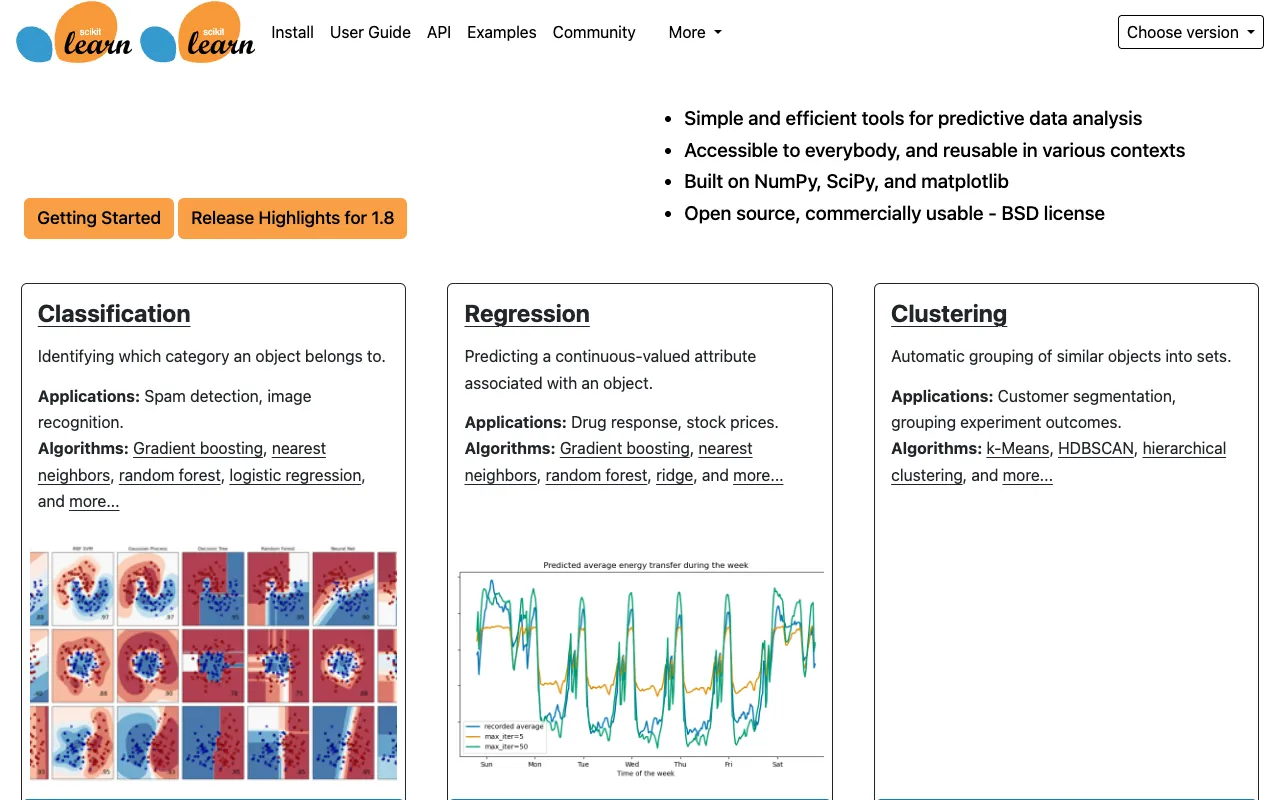
Scikit-learn – La Bibliothèque Indispensable de Machine Learning pour les Data Scientists
Scikit-learn est la pierre angulaire du machine learning pratique en Python. En tant que bibliothèque la plus largement adoptée pour l'analyse prédictive des données, elle offre aux data scientists une API cohérente et intuitive pour mettre en œuvre une vaste gamme d'algorithmes de classification, régression et clustering. Construite sur les solides fondations de NumPy, SciPy et Matplotlib, Scikit-learn transforme la modélisation statistique complexe en flux de travail accessibles et efficaces, ce qui en fait le premier choix pour le prototypage, la recherche et les applications de ML en production.
Qu'est-ce que Scikit-learn ?
Scikit-learn est une bibliothèque Python complète et open-source conçue spécifiquement pour le machine learning et la modélisation statistique. Son objectif principal est de fournir des outils accessibles et efficaces pour l'analyse prédictive des données, servant de pont pratique entre la théorie statistique et les projets réels de data science. La bibliothèque est conçue pour un large public, des étudiants et chercheurs académiques aux data scientists et ingénieurs ML de l'industrie, offrant une interface unifiée qui simplifie l'intégralité du pipeline de ML—de la prétraitement des données et la sélection de modèle à l'entraînement, l'évaluation et le déploiement.
Fonctionnalités Clés de Scikit-learn
API Unifiée pour une Modélisation Cohérente
La plus grande force de Scikit-learn est son API d'estimateur cohérente. Que vous utilisiez une régression linéaire, une machine à vecteurs de support ou une forêt aléatoire, les méthodes `.fit()`, `.predict()` et `.score()` fonctionnent de manière identique. Cela réduit considérablement la courbe d'apprentissage et la complexité du code, permettant aux data scientists d'expérimenter et de comparer rapidement des dizaines d'algorithmes sans réécrire leur flux de travail.
Bibliothèque d'Algorithmes Complète
La bibliothèque propose une vaste collection éprouvée d'algorithmes d'apprentissage supervisé et non supervisé. Cela inclut tout, des modèles linéaires classiques et machines à vecteurs de support aux méthodes d'ensemble comme les Forêts Aléatoires et le Gradient Boosting, ainsi que des algorithmes de clustering comme K-Means et DBSCAN. Cette approche 'tout-en-un' élimine le besoin d'intégrer de multiples paquets spécialisés pour la plupart des tâches de ML courantes.
Outils Intégrés de Sélection et d'Évaluation de Modèles
Scikit-learn fournit des utilitaires intégrés pour les étapes critiques du cycle de vie du ML. Cela inclut des outils pour la validation croisée (comme `cross_val_score` et `GridSearchCV`), l'optimisation des hyperparamètres et une suite complète de métriques pour l'évaluation des modèles (précision, rappel, score F1, ROC-AUC, etc.). Ces fonctionnalités intégrées assurent un développement de modèle robuste et préviennent les écueils d'évaluation courants.
Pipeline de Prétraitement des Données Transparent
Au-delà des algorithmes, Scikit-learn excelle dans la préparation des données grâce à ses modules `preprocessing` et `decomposition`. Il propose des solutions évolutives pour la mise à l'échelle des caractéristiques (StandardScaler, MinMaxScaler), l'encodage des variables catégorielles (OneHotEncoder), la gestion des valeurs manquantes (SimpleImputer) et la réduction de dimensionnalité (PCA, t-SNE). L'objet `Pipeline` vous permet d'enchaîner ces étapes de prétraitement avec un estimateur, créant ainsi des flux de travail reproductibles et déployables.
Qui Devrait Utiliser Scikit-learn ?
Scikit-learn est l'outil idéal pour toute personne travaillant sur des projets de machine learning au sein de l'écosystème Python. Il est indispensable pour les **Data Scientists** qui prototypent et valident des modèles, les **Ingénieurs ML** qui construisent des pipelines en production, les **Chercheurs Académiques** nécessitant des expériences reproductibles, et les **Étudiants** apprenant le machine learning appliqué. Ses cas d'usage couvrent des secteurs allant de la finance (pour la détection de fraude et la modélisation du risque) et la santé (pour la prédiction des résultats des patients) au e-commerce (pour les systèmes de recommandation et la segmentation client) et tout domaine nécessitant une prédiction ou une découverte de motifs basée sur les données.
Tarification de Scikit-learn et Version Gratuite
Scikit-learn est un logiciel entièrement **gratuit et open-source** publié sous licence BSD. Il n'y a pas de version payante, d'abonnement ou de version premium. L'intégralité de la bibliothèque—incluant tous les algorithmes, outils de prétraitement et utilitaires—est disponible pour un usage commercial et non commercial sans aucun coût. Le développement est soutenu par une large communauté de contributeurs et d'organisations, garantissant sa maintenance continue et son amélioration en tant que bien public pour la communauté de la data science.
Cas d'utilisation courants
- Construire un modèle de prédiction de l'attrition client pour les entreprises SaaS
- Créer un système de classification d'images multiclasses en utilisant l'extraction de caractéristiques
- Segmenter les données démographiques utilisateur pour des campagnes marketing ciblées avec le clustering
- Développer un modèle de scoring de crédit pour l'évaluation du risque financier
Principaux avantages
- Accélère le prototypage et l'expérimentation de modèles en fournissant une interface cohérente pour des dizaines d'algorithmes.
- Améliore la fiabilité des modèles avec des outils intégrés pour une validation rigoureuse, l'optimisation des hyperparamètres et l'évaluation des performances.
- Réduit la dette technique en permettant la création de pipelines de machine learning reproductibles de bout en bout, faciles à maintenir et à déployer.
Avantages et inconvénients
Avantages
- Bibliothèque standard de l'industrie avec un soutien communautaire inégalé et une documentation exhaustive.
- API exceptionnellement bien conçue et cohérente qui simplifie considérablement le flux de travail du machine learning.
- Couverture complète des algorithmes de ML essentiels et des techniques de prétraitement des données dans un seul paquet.
- Entièrement gratuite et open-source avec une licence permissive pour tout cas d'usage.
Inconvénients
- Principalement axée sur le machine learning classique (données tabulaires) ; ce n'est pas un framework pour le deep learning (utilisez TensorFlow/PyTorch pour les réseaux neuronaux).
- Support natif limité pour les jeux de données très volumineux qui ne tiennent pas en mémoire ; peut nécessiter une intégration avec d'autres bibliothèques comme Dask.
- Bien qu'excellente pour la modélisation, ce n'est pas une plateforme data science complète (la manipulation de données est mieux gérée par pandas, et la visualisation par matplotlib/seaborn).
Foire aux questions
Scikit-learn est-il gratuit ?
Oui, absolument. Scikit-learn est un logiciel 100% gratuit et open-source publié sous licence BSD. Vous pouvez l'utiliser pour des projets personnels, académiques ou commerciaux sans aucun coût ni frais de licence.
Scikit-learn est-il bon pour le deep learning ?
Non, Scikit-learn n'est pas conçu pour le deep learning. Il excelle dans les algorithmes de machine learning classique pour les données tabulaires (comme les modèles linéaires, SVM, ensembles d'arbres). Pour les tâches de deep learning impliquant des réseaux neuronaux (par ex., vision par ordinateur, NLP), vous devez utiliser des frameworks dédiés comme TensorFlow, PyTorch ou Keras.
Quel est le principal avantage d'utiliser Scikit-learn ?
Le principal avantage est son API unifiée et cohérente, qui rend l'ensemble du processus de machine learning—de l'essai de différents algorithmes à leur évaluation et optimisation—incroyablement efficace et moins sujet aux erreurs. Cette cohérence est la raison pour laquelle c'est le point de départ par défaut pour la plupart des projets de ML en Python.
Comment Scikit-learn se compare-t-il aux autres outils de data science ?
Scikit-learn se spécialise dans la modélisation en machine learning. Il est typiquement utilisé aux côtés de pandas pour la manipulation des données, NumPy pour le calcul numérique, et matplotlib/seaborn pour la visualisation. Il complète plutôt qu'il ne remplace ces bibliothèques, formant le cœur de la stack data science Python pour l'analyse prédictive.
Conclusion
Scikit-learn reste la fondation incontestée du machine learning appliqué en Python. Pour les data scientists qui s'attaquent à des problèmes d'analyse prédictive, de classification, de régression ou de clustering, il offre une combinaison inégalée d'accessibilité, de robustesse et d'outillage complet. Sa nature gratuite, open-source et sa communauté dynamique garantissent qu'il continuera d'évoluer en tant que ressource essentielle. Que vous construisiez votre premier modèle ou que vous déployiez un pipeline complexe en production, Scikit-learn fournit la boîte à outils fiable, efficace et bien documentée dont vous avez besoin pour réussir.