Scikit-learn – 数据科学家必备的机器学习库
Scikit-learn是Python中实用机器学习的基石。作为预测性数据分析领域应用最广泛的库,它为数据科学家提供了一致、直观的API,用于实现大量分类、回归和聚类算法。基于NumPy、SciPy和Matplotlib的坚实基础构建,Scikit-learn将复杂的统计建模转化为易于使用、高效的工作流程,使其成为原型设计、研究和生产级机器学习应用的首选。
什么是Scikit-learn?
Scikit-learn是一个专门为机器学习和统计建模设计的全面、开源的Python库。其主要目的是为预测性数据分析提供易于使用且高效的工具,充当统计理论与实际数据科学项目之间的实践桥梁。该库面向广泛的受众,从学生和学术研究人员到行业数据科学家和机器学习工程师,提供了一个统一的接口,简化了整个机器学习流程——从数据预处理和模型选择到训练、评估和部署。
Scikit-learn的主要特性
一致建模的统一API
Scikit-learn的最大优势在于其一致的估算器API。无论您使用的是线性回归、支持向量机还是随机森林,`.fit()`、`.predict()`和`.score()`方法都以相同的方式工作。这极大地降低了学习曲线和代码复杂度,使数据科学家能够快速试验和比较数十种算法,而无需重写工作流程。
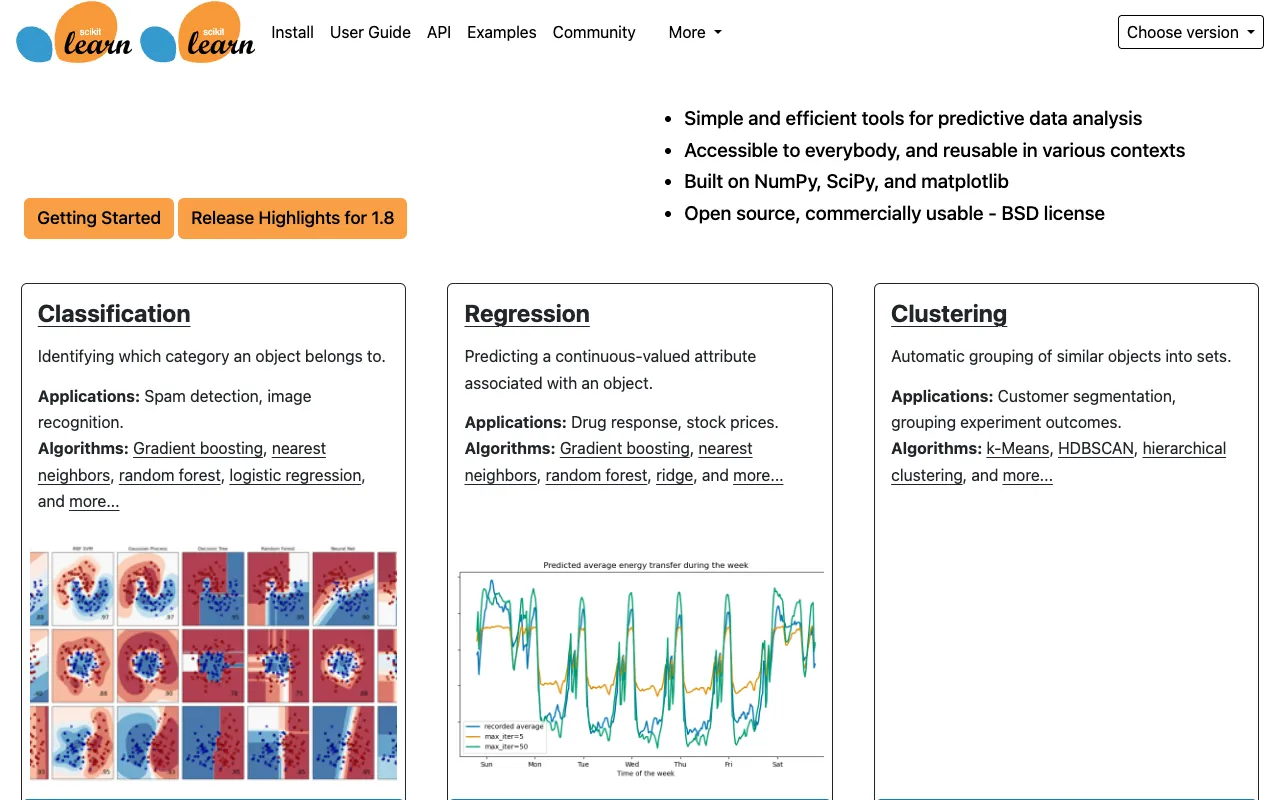
全面的算法库
该库提供了大量经过实战检验的监督和无监督学习算法。这包括从经典的线性模型和支持向量机到集成方法如随机森林和梯度提升,以及聚类算法如K-Means和DBSCAN等。这种‘一站式’方法消除了为大多数常见机器学习任务集成多个专门包的需要。
集成的模型选择与评估工具
Scikit-learn为机器学习生命周期的关键步骤提供了内置工具。这包括用于交叉验证(如`cross_val_score`和`GridSearchCV`)、超参数调优的工具,以及一套完整的模型评估指标(准确率、精确率、召回率、F1分数、ROC-AUC等)。这些集成功能确保了稳健的模型开发,并防止了常见的评估陷阱。
无缝的数据预处理流程
除了算法,Scikit-learn还通过其`preprocessing`和`decomposition`模块在数据准备方面表现出色。它提供了可扩展的解决方案,用于特征缩放(StandardScaler、MinMaxScaler)、编码分类变量(OneHotEncoder)、处理缺失值(SimpleImputer)和降维(PCA、t-SNE)。`Pipeline`对象允许您将这些预处理步骤与估算器链接起来,创建可重复且可部署的工作流程。
谁应该使用Scikit-learn?
Scikit-learn是任何在Python生态系统中从事机器学习项目的人的理想工具。它对于原型设计和验证模型的**数据科学家**、构建生产管道的**机器学习工程师**、需要可重复实验的**学术研究人员**,以及学习应用机器学习的**学生**来说都是不可或缺的。其用例涵盖各行各业,从金融(用于欺诈检测和风险建模)和医疗保健(用于患者结果预测),到电子商务(用于推荐系统和客户细分),以及任何需要数据驱动预测或模式发现的领域。
Scikit-learn定价与免费层级
Scikit-learn是完全**免费和开源**的软件,根据BSD许可证发布。没有付费层级、订阅或高级版本。整个库——包括所有算法、预处理工具和实用程序——都可以免费用于商业和非商业用途。其开发由一个庞大的贡献者和组织社区支持,确保其作为数据科学社区的公共产品得到持续的维护和改进。
常见用例
- 为SaaS企业构建客户流失预测模型
- 使用特征提取创建多类图像分类系统
- 通过聚类对用户人口统计数据进行细分,用于定向营销活动
- 开发用于金融风险评估的信用评分模型
主要好处
- 通过为数十种算法提供一致的接口,加速模型原型设计和实验。
- 通过内置的严格验证、超参数调优和性能评估工具,增强模型可靠性。
- 通过创建可重复、端到端的机器学习管道,减少技术债务,便于维护和部署。
优点和缺点
优点
- 行业标准库,拥有无与伦比的社区支持和广泛的文档。
- 设计极其精良、一致的API,极大地简化了机器学习工作流程。
- 在一个包中全面覆盖了基本机器学习算法和数据预处理技术。
- 完全免费开源,拥有适用于任何用例的宽松许可证。
缺点
- 主要专注于经典机器学习(表格数据);不是深度学习框架(对于神经网络,请使用TensorFlow/PyTorch)。
- 对无法装入内存的超大数据集的原生支持有限;可能需要与Dask等其他库集成。
- 虽然建模方面非常出色,但它不是一个全栈数据科学平台(数据操作最好由pandas处理,可视化最好由matplotlib/seaborn处理)。
常见问题
Scikit-learn免费使用吗?
是的,完全免费。Scikit-learn是100%免费开源软件,根据BSD许可证发布。您可以将其用于个人、学术或商业项目,无需任何成本或许可费。
Scikit-learn适合深度学习吗?
不,Scikit-learn不是为深度学习设计的。它擅长处理表格数据的经典机器学习算法(如线性模型、支持向量机、基于树的集成算法)。对于涉及神经网络(例如计算机视觉、自然语言处理)的深度学习任务,您应该使用专门的框架,如TensorFlow、PyTorch或Keras。
使用Scikit-learn的主要优势是什么?
主要优势在于其统一且一致的API,这使得整个机器学习过程——从尝试不同算法到评估和调优它们——变得极其高效且不易出错。这种一致性是为什么它成为大多数Python机器学习项目的默认起点的原因。
Scikit-learn与其他数据科学工具相比如何?
Scikit-learn专门用于机器学习建模。它通常与用于数据操作的pandas、用于数值计算的NumPy以及用于可视化的matplotlib/seaborn一起使用。它补充而不是取代这些库,构成了用于预测分析的Python数据科学堆栈的核心。
结论
Scikit-learn仍然是Python中应用机器学习无可争议的基石。对于处理预测分析、分类、回归或聚类问题的数据科学家来说,它提供了无与伦比的易用性、鲁棒性和全面工具组合。其免费、开源的性质和充满活力的社区确保了它将继续发展成为一个必不可少的资源。无论您是构建第一个模型还是将复杂的管道部署到生产环境,Scikit-learn都提供了您成功所需的可靠、高效且文档齐全的工具包。