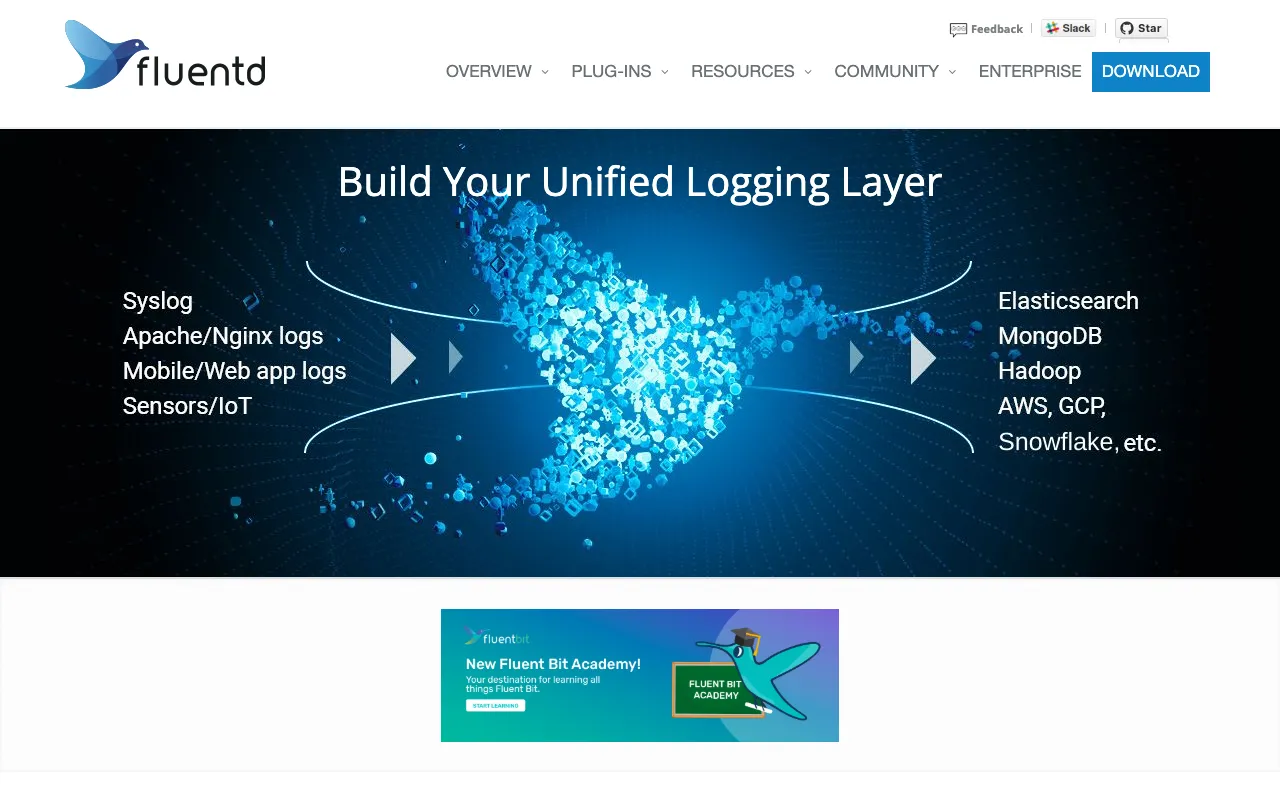
Fluentd – Der essentielle Open-Source-Log-Datensammler für DevOps
Fluentd ist der branchenübliche Open-Source-Datensammler, der eine einheitliche Logging-Schicht für Ihre gesamte DevOps-Infrastruktur schafft. Er löst die kritische Herausforderung des Log-Managements im großen Maßstab, indem er Logs aus Hunderten von Datenquellen (Anwendungen, Server, Container, Datenbanken) sammelt, sie in Echtzeit verarbeitet und zuverlässig an Dutzende von Zielen wie Elasticsearch, S3, Datadog oder Slack weiterleitet. Als Kernkomponente der CNCF-Landschaft wird Fluentd von Unternehmen weltweit genutzt, um robuste, skalierbare Observability-Pipelines aufzubauen, die Ingenieure mit handlungsrelevanten Erkenntnissen befähigen.
Was ist Fluentd?
Fluentd ist ein verteilter, Open-Source-Datensammler-Daemon, geschrieben in Ruby und C. Seine Hauptaufgabe ist es, als einheitliche Logging-Schicht zu fungieren und Datenquellen von Backend-Systemen zu entkoppeln. Man kann ihn sich als 'Log-Router' vorstellen, der zwischen Ihren Anwendungen/Infrastruktur und Ihren Analyse- oder Speichersystemen sitzt. Er standardisiert Datenformate (in JSON), bietet Pufferung und Wiederholungslogik für Zuverlässigkeit und ermöglicht flexible Datentransformation und -filterung. Dieser Ansatz ist grundlegend für moderne DevOps-Praktiken wie zentralisiertes Logging, Monitoring und Analytics und ermöglicht Teams einen ganzheitlichen Blick auf ihre Systeme, unabhängig von der zugrunde liegenden Technologie.
Hauptfunktionen von Fluentd
Einheitliches Logging mit JSON
Fluentd strukturiert alle Daten als JSON und bietet so ein gemeinsames Format für die Verarbeitung von Logdaten in Ihrem gesamten Stack. Diese Standardisierung vereinfacht das Parsen, Filtern und Anreichern und macht Logs aus unterschiedlichen Quellen (Nginx, Docker, Java-Apps, Kernel-Logs) sofort für nachgelagerte Analysetools nutzbar.
Plug-in-Architektur
Seine Stärke liegt in einem riesigen Ökosystem von über 500 community-beigetragenen Plug-ins. 'Input'-Plug-ins sammeln Daten von Quellen wie syslog, HTTP, TCP oder Docker. 'Filter'-Plug-ins parsen und transformieren Daten (z.B. grep, record_transformer). 'Output'-Plug-ins leiten Daten an Ziele wie Elasticsearch, Amazon S3, Kafka oder Slack weiter. Diese Erweiterbarkeit macht Fluentd an nahezu jede Umgebung anpassbar.
Integrierte Zuverlässigkeit
Fluentd behandelt Ausfälle elegant mit speicher- und dateibasierter Pufferung, um Datenverlust zu verhindern. Wenn ein Ziel wie Elasticsearch nicht verfügbar ist, versucht Fluentd erneut, die Daten zu senden, und gewährleistet so die Integrität der Logdaten – eine entscheidende Funktion für Produktionssysteme und Audit-Trails.
Geringer Ressourcenverbrauch
Die Kern-Engine ist in C mit einem Ruby-Wrapper für Flexibilität geschrieben, was zu hoher Leistung bei geringem Speicherverbrauch (ca. 30–40 MB) führt. Das macht ihn ideal für den Einsatz als Sidecar-Container in Kubernetes oder als Daemon auf virtuellen Maschinen.
Für wen ist Fluentd geeignet?
Fluentd ist unverzichtbar für DevOps-Ingenieure, SREs und Platform-Teams, die Cloud-native oder hybride Infrastrukturen verwalten. Es ist perfekt für Organisationen, die ihre Observability-Strategie implementieren oder skalieren, insbesondere für diejenigen, die Kubernetes verwenden (wo es oft als Fluent Bit oder Fluentd DaemonSets bereitgestellt wird), Microservices-Architekturen oder Multi-Cloud-Bereitstellungen. Wenn Sie mit fragmentierten Logs kämpfen, eine Datenpipeline für Security Information and Event Management (SIEM) aufbauen oder eine zuverlässige Methode benötigen, um Daten in einen Data Lake oder eine Echtzeit-Analyseplattform einzuspeisen, ist Fluentd die grundlegende Schicht, die Sie brauchen.
Fluentd Preise und Free Tier
Fluentd ist zu 100 % Open-Source-Software unter der Apache License 2.0 lizenziert. Es fallen keine Kosten für den Download, die Nutzung oder Bereitstellung von Fluentd an, was es zu einer äußerst kosteneffizienten Lösung für die Log-Aggregation macht. Die gesamte Kernfunktionalität und das umfangreiche Plug-in-Ökosystem sind frei verfügbar. Kommerzieller Support und Enterprise-Distributionen (wie TD Agent) werden von Treasure Data, dem ursprünglichen Schöpfer, für Organisationen angeboten, die garantierte SLAs und professionelle Dienstleistungen benötigen.
Häufige Anwendungsfälle
- Zentralisiertes Logging für Kubernetes- und Docker-Container-Umgebungen
- Aufbau einer Log-Analytics-Pipeline für Sicherheit und Compliance (SIEM-Integration)
- Echtzeit-Log-Streaming zu Apache Kafka für Event-driven-Architekturen
- Aggregation von Anwendungslogs aus Microservices für einheitliches Debugging und Monitoring
Hauptvorteile
- Beseitigt Datensilos durch eine einheitliche Ansicht aller Logdaten und reduziert so drastisch die mittlere Reparaturzeit (MTTR) bei Vorfällen.
- Reduziert operative Komplexität und Kosten durch den Ersatz mehrerer Point-Lösungen durch einen flexiblen, skalierbaren Datensammler.
- Zukunftssichert Ihre Logging-Infrastruktur mit einem herstellerneutralen, community-getriebenen Standard, der sich in jedes Tool integrieren lässt.
Vor- & Nachteile
Vorteile
- Völlig kostenlos und Open-Source mit einer riesigen, aktiven Community.
- Äußerst flexibel und erweiterbar durch ein reichhaltiges Plug-in-Ökosystem.
- Bewährt im Petabyte-Maßstab im Produktionseinsatz bei großen Unternehmen.
- Cloud-nativ konzipiert mit First-Class-Support für Kubernetes und Docker.
- Bietet zuverlässige Datenlieferung mit Pufferungs- und Wiederholungsmechanismen.
Nachteile
- Die Konfiguration kann für fortgeschrittene Anwendungsfälle komplex sein und erfordert eine Lernkurve.
- Der Ruby-basierte Kern kann im Vergleich zu reinen C/C++-Alternativen wie Fluent Bit für Edge-Collection einen höheren Speicherverbrauch haben.
- Die Verwaltung eines hochverfügbaren Fluentd-Clusters erfordert sorgfältige Planung und operationelles Know-how.
Häufig gestellte Fragen
Ist Fluentd kostenlos nutzbar?
Ja, Fluentd ist vollständig kostenlos und Open-Source. Sie können es in jeder Umgebung – von einem einzelnen Server bis zu einem globalen Unternehmenscluster – herunterladen, bereitstellen und nutzen, ohne Lizenzgebühren zu zahlen. Der Quellcode ist öffentlich auf GitHub unter der Apache-2.0-Lizenz verfügbar.
Was ist der Unterschied zwischen Fluentd und Fluent Bit?
Fluentd ist ein vollwertiger Datensammler für den Aufbau komplexer, zuverlässiger Logging-Pipelines auf Servern. Fluent Bit ist ein leichterer, schnellerer Forwarder, der für Edge-Collection konzipiert ist, z. B. auf IoT-Geräten oder in einzelnen Containern. Sie ergänzen sich: Fluent Bit kann Daten an Fluentd zur Aggregation und Verarbeitung weiterleiten. Für DevOps auf Kubernetes wird Fluent Bit oft als DaemonSet auf Nodes eingesetzt, der an eine zentralisierte Fluentd-Instanz weiterleitet.
Ist Fluentd gut für DevOps-Ingenieure?
Absolut. Fluentd gilt als grundlegendes Werkzeug im DevOps-Werkzeugkasten. Es adressiert direkt den DevOps-Bedarf an umfassender Observability, indem es Logs über Entwicklung und Betrieb hinweg vereinheitlicht. Es ermöglicht schnelleres Debugging, besseres Monitoring und datengesteuerte Entscheidungsfindung, die Kernaspekte der DevOps-Kultur sind. Seine Integration in CI/CD-Pipelines, Infrastructure as Code und Container-Orchestrierung macht es perfekt für moderne DevOps-Workflows.
Fazit
Für DevOps-Teams, die ihre Observability-Daten beherrschen wollen, ist Fluentd nicht nur ein Werkzeug – es ist eine strategische Grundlage. Seine Fähigkeit, aus heterogenen Quellen eine einheitliche, zuverlässige und flexible Logging-Schicht zu schaffen, ist in der Open-Source-Welt unübertroffen. Während es für bestimmte Nischen Alternativen gibt, machen seine Reife, das umfangreiche Plug-in-Ökosystem und die bewiesene Skalierbarkeit Fluentd zur Standardwahl für ernsthafte Log-Aggregation-Pipelines. Wenn Ihr Ziel ist, eine robuste, herstellerunabhängige Observability-Plattform aufzubauen, die mit Ihrer Infrastruktur wachsen kann, dann ist der Start mit Fluentd eine der wirkungsvollsten architektonischen Entscheidungen, die Sie treffen können.