Fluentd – The Essential Open-Source Log Data Collector for DevOps
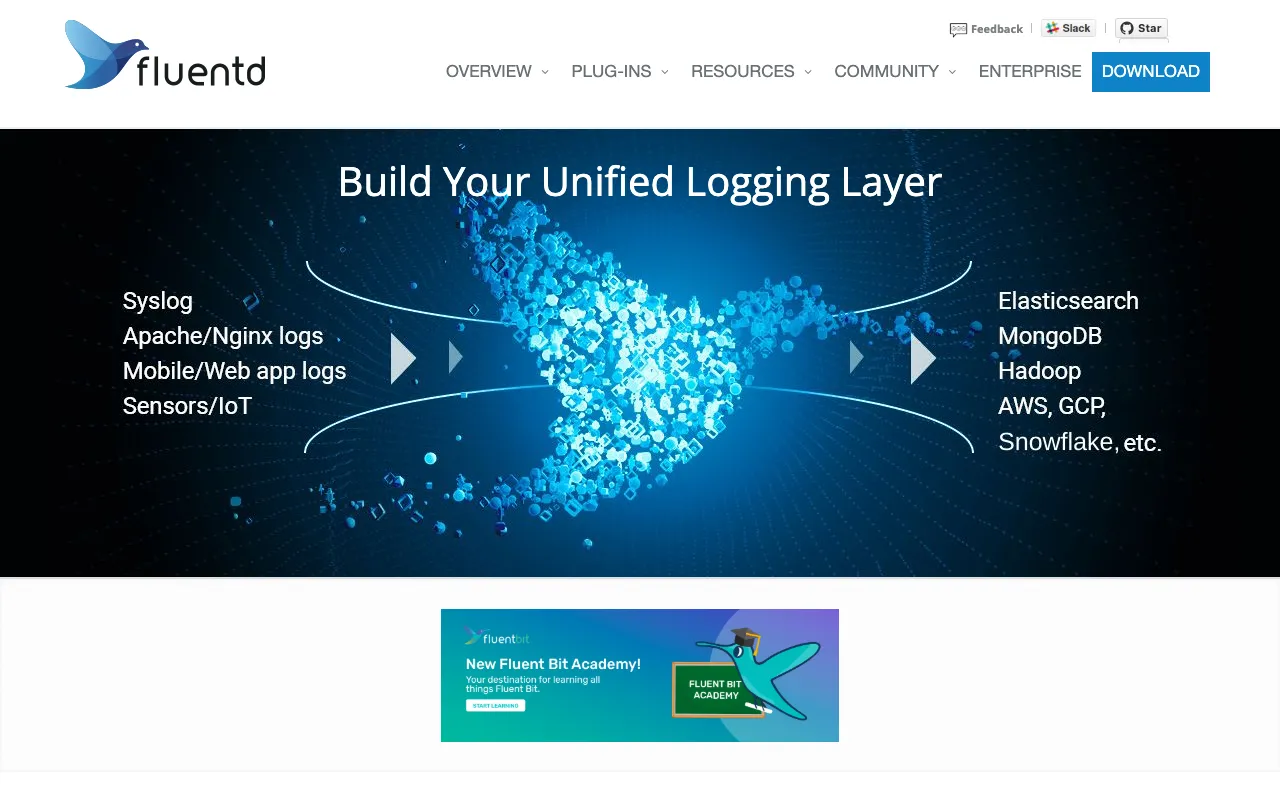
Fluentd is the industry-standard open-source data collector that creates a unified logging layer for your entire DevOps infrastructure. It solves the critical challenge of log management at scale by collecting logs from hundreds of data sources (applications, servers, containers, databases), processing them in real-time, and reliably routing them to dozens of destinations like Elasticsearch, S3, Datadog, or Slack. As a core component of the CNCF landscape, Fluentd is trusted by enterprises worldwide to build robust, scalable observability pipelines that empower engineers with actionable insights.
What is Fluentd?
Fluentd is a distributed, open-source data collection daemon written in Ruby and C. Its primary purpose is to act as a unified logging layer, decoupling data sources from backend systems. Think of it as a 'log router' that sits between your applications/infrastructure and your analytics or storage systems. It standardizes data formats (into JSON), provides buffering and retry logic for reliability, and allows for flexible data transformation and filtering. This approach is foundational for modern DevOps practices like centralized logging, monitoring, and analytics, enabling teams to gain a holistic view of their systems regardless of the underlying technology stack.
Key Features of Fluentd
Unified Logging with JSON
Fluentd structures all data as JSON, providing a common format for processing log data across your entire stack. This standardization simplifies parsing, filtering, and enrichment, making logs from disparate sources (Nginx, Docker, Java apps, kernel logs) immediately usable by downstream analytics tools.
Pluggable Architecture
Its strength lies in a vast ecosystem of over 500 community-contributed plugins. 'Input' plugins collect data from sources like syslog, HTTP, TCP, or Docker. 'Filter' plugins parse and transform data (e.g., grep, record_transformer). 'Output' plugins route data to destinations like Elasticsearch, Amazon S3, Kafka, or Slack. This extensibility makes Fluentd adaptable to virtually any environment.
Built-in Reliability
Fluentd handles failure gracefully with memory and file-based buffering to prevent data loss. If a destination like Elasticsearch becomes unavailable, Fluentd will retry sending the data, ensuring log data integrity—a critical feature for production systems and audit trails.
Low Resource Footprint
The core engine is written in C with a Ruby wrapper for flexibility, resulting in high performance with a small memory footprint (approx. 30-40MB). This makes it ideal for deployment as a sidecar container in Kubernetes or as a daemon on virtual machines.
Who Should Use Fluentd?
Fluentd is indispensable for DevOps engineers, SREs, and platform teams managing cloud-native or hybrid infrastructure. It's perfect for organizations implementing or scaling their observability strategy, especially those using Kubernetes (where it's often deployed as Fluent Bit or Fluentd daemonsets), microservices architectures, or multi-cloud deployments. If you're struggling with fragmented logs, building a data pipeline for security information and event management (SIEM), or need a reliable way to feed data into a data lake or real-time analytics platform, Fluentd is the foundational layer you need.
Fluentd Pricing and Free Tier
Fluentd is 100% open-source software licensed under the Apache License 2.0. There is no cost to download, use, or deploy Fluentd, making it an incredibly cost-effective solution for log aggregation. The entire core functionality and the extensive plugin ecosystem are freely available. Commercial support and enterprise distributions (like TD Agent) are offered by Treasure Data, the original creator, for organizations requiring guaranteed SLAs and professional services.
Common Use Cases
- Centralized logging for Kubernetes and Docker container environments
- Building a log analytics pipeline for security and compliance (SIEM integration)
- Real-time log streaming to Apache Kafka for event-driven architectures
- Aggregating application logs from microservices for unified debugging and monitoring
Key Benefits
- Eliminates data silos by providing a single pane of glass for all log data, drastically reducing mean time to resolution (MTTR) for incidents.
- Reduces operational complexity and cost by replacing multiple point solutions with one flexible, scalable data collector.
- Future-proofs your logging infrastructure with a vendor-neutral, community-driven standard that integrates with any tool.
Pros & Cons
Pros
- Completely free and open-source with a massive, active community.
- Extremely flexible and extensible via a rich plugin ecosystem.
- Proven at petabyte scale in production by major enterprises.
- Cloud-native by design, with first-class support for Kubernetes and Docker.
- Provides reliable data delivery with buffering and retry mechanisms.
Cons
- Configuration can be complex for advanced use cases, requiring a learning curve.
- The Ruby-based core can have higher memory usage compared to purely C/C++ alternatives like Fluent Bit for edge collection.
- Managing a high-availability Fluentd cluster requires careful planning and operational knowledge.
Frequently Asked Questions
Is Fluentd free to use?
Yes, Fluentd is completely free and open-source. You can download, deploy, and use it in any environment—from a single server to a global enterprise cluster—without any licensing fees. The source code is publicly available on GitHub under the Apache 2.0 license.
What is the difference between Fluentd and Fluent Bit?
Fluentd is a full-featured data collector for building complex, reliable logging pipelines on servers. Fluent Bit is a lighter-weight, faster forwarder designed for edge collection, such as on IoT devices or within individual containers. They are complementary: Fluent Bit can forward data to Fluentd for aggregation and processing. For DevOps on Kubernetes, Fluent Bit is often used as a daemonset on nodes, forwarding to a centralized Fluentd instance.
Is Fluentd good for DevOps engineers?
Absolutely. Fluentd is considered a fundamental tool in the DevOps toolkit. It directly addresses the DevOps need for comprehensive observability by unifying logs across development and operations. It enables faster debugging, better monitoring, and data-driven decision-making, which are core to DevOps culture. Its integration with CI/CD pipelines, infrastructure as code, and container orchestration makes it a perfect fit for modern DevOps workflows.
Conclusion
For DevOps teams seeking to master their observability data, Fluentd is not just a tool—it's a strategic foundation. Its ability to create a unified, reliable, and flexible logging layer from heterogeneous sources is unmatched in the open-source world. While alternatives exist for specific niches, Fluentd's maturity, extensive plugin ecosystem, and proven scalability make it the default choice for serious log aggregation pipelines. If your goal is to build a robust, vendor-agnostic observability platform that can grow with your infrastructure, starting with Fluentd is one of the most impactful architectural decisions you can make.