Fluentd – DevOpsのための必須オープンソースログデータコレクター
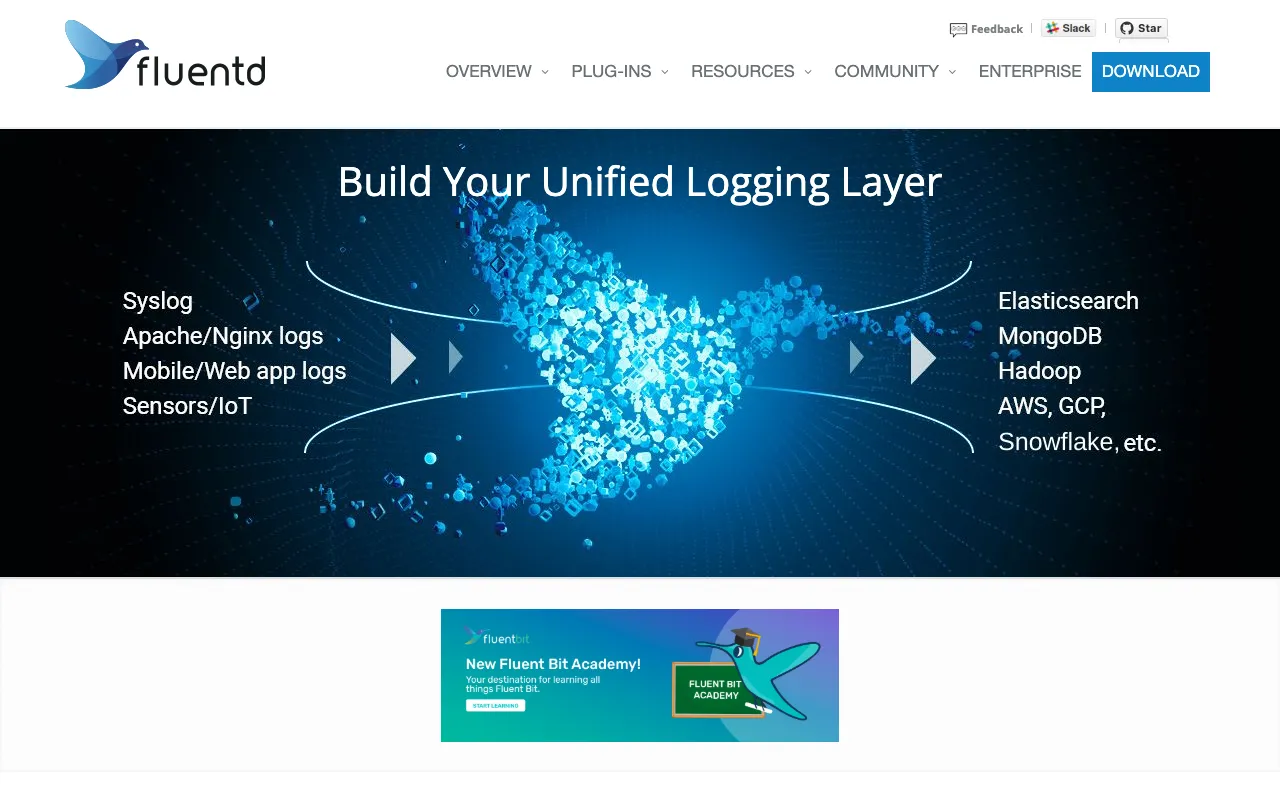
Fluentdは、DevOpsインフラ全体の統一ログレイヤーを構築する業界標準のオープンソースデータコレクターです。数百のデータソース(アプリケーション、サーバー、コンテナ、データベース)からログを収集し、リアルタイムで処理し、Elasticsearch、S3、Datadog、Slackなどの数十の宛先に確実にルーティングすることで、大規模なログ管理の重要な課題を解決します。CNCFランドスケープのコアコンポーネントとして、Fluentdは世界中の企業に信頼され、エンジニアに実用的なインサイトを提供する堅牢でスケーラブルなオブザーバビリティパイプラインの構築を可能にします。
Fluentdとは?
Fluentdは、RubyとCで書かれた分散型のオープンソースデータ収集デーモンです。その主な目的は、データソースとバックエンドシステムを分離する統一ログレイヤーとして機能することです。アプリケーション/インフラと分析・ストレージシステムの間に位置する「ログルーター」と考えてください。データ形式をJSONに標準化し、信頼性のためのバッファリングと再試行ロジックを提供し、柔軟なデータ変換とフィルタリングを可能にします。このアプローチは、集中ログ管理、モニタリング、分析などの現代のDevOpsプラクティスの基礎であり、基盤となるテクノロジースタックに関係なくシステム全体を包括的に把握できるようにします。
Fluentdの主な機能
JSONによる統一ログ管理
FluentdはすべてのデータをJSONとして構造化し、スタック全体でログデータを処理するための共通フォーマットを提供します。この標準化により、解析、フィルタリング、エンリッチメントが簡素化され、異種ソース(Nginx、Docker、Javaアプリ、カーネルログ)からのログが下流の分析ツールで即座に利用可能になります。
プラグイン可能なアーキテクチャ
その強みは、500以上にも及ぶコミュニティ提供のプラグインの豊富なエコシステムにあります。「入力」プラグインは、syslog、HTTP、TCP、Dockerなどのソースからデータを収集します。「フィルター」プラグインはデータを解析・変換します(例:grep、record_transformer)。「出力」プラグインは、データをElasticsearch、Amazon S3、Kafka、Slackなどの宛先にルーティングします。この拡張性により、Fluentdは事実上あらゆる環境に適応できます。
組み込みの信頼性
Fluentdは、メモリおよびファイルベースのバッファリングでデータ損失を防ぎ、障害を適切に処理します。Elasticsearchなどの宛先が利用不能になった場合、Fluentdはデータの送信を再試行し、ログデータの完全性を確保します。これは、本番システムと監査証跡にとって重要な機能です。
低リソースフットプリント
コアエンジンはCで書かれており、柔軟性のためにRubyラッパーが付いています。その結果、高いパフォーマンスと小さなメモリフットプリント(約30-40MB)を実現しています。これは、Kubernetesのサイドカーコンテナとして、または仮想マシンのデーモンとしてデプロイするのに理想的です。
誰がFluentdを使うべきか?
Fluentdは、クラウドネイティブまたはハイブリッドインフラを管理するDevOpsエンジニア、SRE、プラットフォームチームにとって不可欠です。特に、Kubernetes(Fluent BitまたはFluentdデーモンセットとしてデプロイされることが多い)を使用している組織、マイクロサービスアーキテクチャ、またはマルチクラウドデプロイメントで、オブザーバビリティ戦略を実装または拡大している組織に最適です。断片化したログに悩んでいる場合、セキュリティ情報およびイベント管理(SIEM)のためのデータパイプラインを構築している場合、またはデータレイクやリアルタイム分析プラットフォームにデータを供給する信頼性の高い方法が必要な場合、Fluentdは必要な基盤レイヤーです。
Fluentdの価格と無料利用枠
Fluentdは、Apache License 2.0でライセンスされた100%のオープンソースソフトウェアです。Fluentdをダウンロード、使用、デプロイするためのコストは一切かからず、ログ集約のための非常に費用対効果の高いソリューションです。すべてのコア機能と豊富なプラグインエコシステムは無料で利用できます。保証されたSLAとプロフェッショナルサービスを必要とする組織向けに、オリジナルの作成者であるTreasure Dataによって、商用サポートおよびエンタープライズディストリビューション(TD Agentなど)が提供されています。
一般的な使用例
- KubernetesおよびDockerコンテナ環境のための集中ログ管理
- セキュリティとコンプライアンスのためのログ分析パイプライン構築(SIEM統合)
- イベント駆動型アーキテクチャのためのApache Kafkaへのリアルタイムログストリーミング
- マイクロサービスからのアプリケーションログを集約し、統一されたデバッグとモニタリングを実現
主な利点
- すべてのログデータの単一ペインを提供することでデータサイロを解消し、インシデントの平均解決時間(MTTR)を大幅に短縮します。
- 複数のポイントソリューションを、1つの柔軟でスケーラブルなデータコレクターに置き換えることで、運用の複雑さとコストを削減します。
- あらゆるツールと統合可能な、ベンダー中立でコミュニティ主導の標準により、ログインフラを将来にわたって確実なものにします。
長所と短所
長所
- 大規模で活発なコミュニティを持つ、完全に無料のオープンソースです。
- 豊富なプラグインエコシステムにより、非常に柔軟で拡張可能です。
- 主要企業による本番環境でのペタバイト規模での実績があります。
- クラウドネイティブ設計で、KubernetesとDockerのファーストクラスサポートを提供します。
- バッファリングと再試行メカニズムによる信頼性の高いデータ配信を実現します。
短所
- 高度なユースケースでは設定が複雑になり、学習曲線が必要です。
- Rubyベースのコアは、エッジコレクション用のFluent Bitのような純粋なC/C++代替と比較して、メモリ使用量が多くなる可能性があります。
- 高可用性Fluentdクラスターの管理には、注意深い計画と運用知識が必要です。
よくある質問
Fluentdは無料で使えますか?
はい、Fluentdは完全に無料のオープンソースです。単一サーバーからグローバルなエンタープライズクラスターまで、あらゆる環境で、ライセンス料なしにダウンロード、デプロイ、使用できます。ソースコードはApache 2.0ライセンスの下、GitHubで公開されています。
FluentdとFluent Bitの違いは何ですか?
Fluentdは、サーバー上で複雑で信頼性の高いロギングパイプラインを構築するためのフル機能のデータコレクターです。Fluent Bitは、IoTデバイスや個々のコンテナ内など、エッジコレクション用に設計された、より軽量で高速なフォワーダーです。これらは補完的関係にあります。Fluent BitはデータをFluentdに転送して集約・処理することができます。Kubernetes上のDevOpsでは、Fluent Bitがノード上のデーモンセットとして使用され、集中化されたFluentdインスタンスに転送されることがよくあります。
FluentdはDevOpsエンジニアに適していますか?
もちろんです。FluentdはDevOpsツールキットの基本的なツールと考えられています。開発と運用の両方にわたるログを統一することで、DevOpsに不可欠な包括的なオブザーバビリティのニーズに直接応えます。DevOps文化の核心である、より迅速なデバッグ、より良いモニタリング、データ駆動型の意思決定を可能にします。CI/CDパイプライン、Infrastructure as Code、コンテナオーケストレーションとの統合により、現代のDevOpsワークフローに最適です。
結論
オブザーバビリティデータを習得しようとするDevOpsチームにとって、Fluentdは単なるツールではなく、戦略的な基盤です。異種ソースから統一された、信頼性が高く柔軟なログレイヤーを作成するその能力は、オープンソースの世界において比類がありません。特定のニッチ向けの代替手段は存在しますが、Fluentdの成熟度、広範なプラグインエコシステム、そして実証済みのスケーラビリティは、本格的なログ集約パイプラインのデフォルト選択肢となっています。あなたのインフラと共に成長できる、堅牢でベンダーに依存しないオブザーバビリティプラットフォームを構築することが目標であれば、Fluentdから始めることは、あなたができる最も影響力のあるアーキテクチャ上の決定の一つです。