Fluentd – O Coletor de Dados de Logs Open-Source Essencial para DevOps
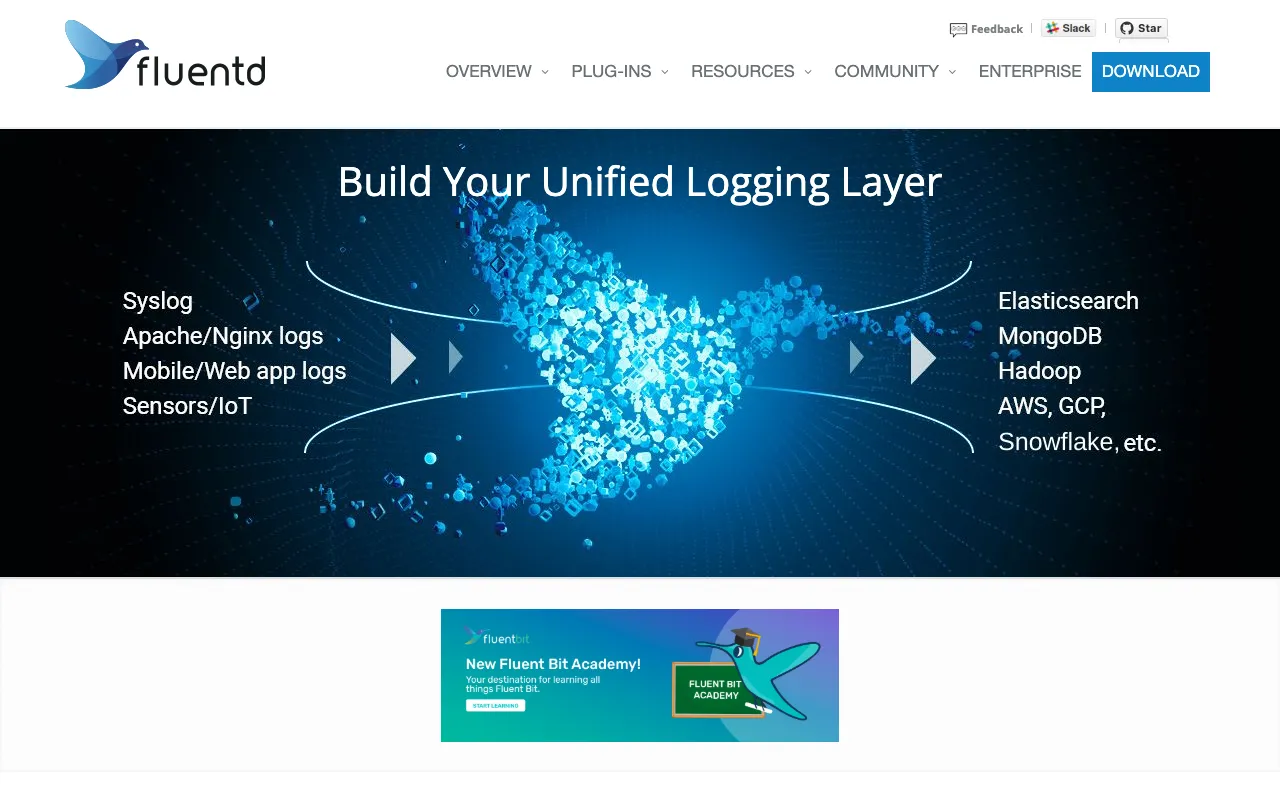
O Fluentd é o coletor de dados open-source padrão do setor que cria uma camada de logging unificada para toda sua infraestrutura DevOps. Ele resolve o desafio crítico do gerenciamento de logs em escala, coletando logs de centenas de fontes (aplicações, servidores, containers, bancos de dados), processando-os em tempo real e roteando-os de forma confiável para dezenas de destinos como Elasticsearch, S3, Datadog ou Slack. Como componente central do ecossistema CNCF, o Fluentd é confiado por empresas em todo o mundo para construir pipelines de observabilidade robustos e escaláveis que capacitam engenheiros com insights acionáveis.
O que é o Fluentd?
O Fluentd é um daemon de coleta de dados distribuído e open-source escrito em Ruby e C. Seu propósito principal é atuar como uma camada de logging unificada, desacoplando as fontes de dados dos sistemas de backend. Pense nele como um 'roteador de logs' que fica entre suas aplicações/infraestrutura e seus sistemas de análise ou armazenamento. Ele padroniza os formatos de dados (para JSON), fornece lógica de buffer e repetição para confiabilidade e permite transformação e filtragem flexível de dados. Essa abordagem é fundamental para práticas modernas de DevOps como logging centralizado, monitoramento e análise, permitindo que as equipes obtenham uma visão holística de seus sistemas independentemente da stack de tecnologia subjacente.
Principais Funcionalidades do Fluentd
Logging Unificado com JSON
O Fluentd estrutura todos os dados como JSON, fornecendo um formato comum para processar dados de logs em toda sua stack. Essa padronização simplifica o parsing, filtragem e enriquecimento, tornando os logs de fontes diferentes (Nginx, Docker, aplicações Java, logs do kernel) imediatamente utilizáveis por ferramentas de análise downstream.
Arquitetura Plugável
Sua força está em um vasto ecossistema de mais de 500 plugins contribuídos pela comunidade. Plugins de 'entrada' coletam dados de fontes como syslog, HTTP, TCP ou Docker. Plugins de 'filtro' analisam e transformam dados (ex: grep, record_transformer). Plugins de 'saída' roteiam dados para destinos como Elasticsearch, Amazon S3, Kafka ou Slack. Essa extensibilidade torna o Fluentd adaptável a praticamente qualquer ambiente.
Confiabilidade Integrada
O Fluentd lida com falhas de forma elegante com buffers baseados em memória e arquivo para evitar perda de dados. Se um destino como o Elasticsearch ficar indisponível, o Fluentd tentará reenviar os dados, garantindo a integridade dos dados de logs — uma funcionalidade crítica para sistemas em produção e trilhas de auditoria.
Baixo Consumo de Recursos
O motor principal é escrito em C com um wrapper em Ruby para flexibilidade, resultando em alto desempenho com uma pequena pegada de memória (aproximadamente 30-40MB). Isso o torna ideal para implantação como um container sidecar no Kubernetes ou como um daemon em máquinas virtuais.
Quem Deve Usar o Fluentd?
O Fluentd é indispensável para engenheiros de DevOps, SREs e equipes de plataforma que gerenciam infraestrutura cloud-native ou híbrida. É perfeito para organizações implementando ou escalando sua estratégia de observabilidade, especialmente aquelas que usam Kubernetes (onde é frequentemente implantado como daemonsets Fluent Bit ou Fluentd), arquiteturas de microsserviços ou implantações multi-cloud. Se você está lutando com logs fragmentados, construindo um pipeline de dados para gerenciamento de informações e eventos de segurança (SIEM), ou precisa de uma maneira confiável de alimentar dados em um data lake ou plataforma de análise em tempo real, o Fluentd é a camada fundamental que você precisa.
Preço e Camada Gratuita do Fluentd
O Fluentd é 100% software open-source licenciado sob a Licença Apache 2.0. Não há custo para baixar, usar ou implantar o Fluentd, tornando-o uma solução incrivelmente custo-efetiva para agregação de logs. Toda a funcionalidade principal e o extenso ecossistema de plugins estão disponíveis gratuitamente. Suporte comercial e distribuições empresariais (como o TD Agent) são oferecidos pela Treasure Data, o criador original, para organizações que exigem SLAs garantidos e serviços profissionais.
Casos de uso comuns
- Logging centralizado para ambientes Kubernetes e Docker container
- Construção de um pipeline de análise de logs para segurança e conformidade (integração SIEM)
- Streaming de logs em tempo real para Apache Kafka para arquiteturas orientadas a eventos
- Agregação de logs de aplicações de microsserviços para depuração e monitoramento unificados
Principais benefícios
- Elimina silos de dados ao fornecer um painel único para todos os dados de logs, reduzindo drasticamente o tempo médio para resolução (MTTR) de incidentes.
- Reduz a complexidade operacional e os custos ao substituir múltiplas soluções pontuais por um coletor de dados flexível e escalável.
- Protege sua infraestrutura de logs para o futuro com um padrão neutro em relação ao fornecedor e orientado pela comunidade que se integra a qualquer ferramenta.
Prós e contras
Prós
- Completamente gratuito e open-source com uma comunidade massiva e ativa.
- Extremamente flexível e extensível através de um rico ecossistema de plugins.
- Comprovado em escala de petabytes em produção por grandes empresas.
- Cloud-native por design, com suporte de primeira classe para Kubernetes e Docker.
- Fornece entrega de dados confiável com mecanismos de buffer e repetição.
Contras
- A configuração pode ser complexa para casos de uso avançados, exigindo uma curva de aprendizado.
- O núcleo baseado em Ruby pode ter maior uso de memória em comparação com alternativas puramente em C/C++, como o Fluent Bit, para coleta na borda.
- Gerenciar um cluster Fluentd de alta disponibilidade requer planejamento cuidadoso e conhecimento operacional.
Perguntas frequentes
O Fluentd é gratuito para usar?
Sim, o Fluentd é completamente gratuito e open-source. Você pode baixar, implantar e usá-lo em qualquer ambiente — de um único servidor a um cluster empresarial global — sem quaisquer taxas de licenciamento. O código-fonte está publicamente disponível no GitHub sob a licença Apache 2.0.
Qual é a diferença entre Fluentd e Fluent Bit?
O Fluentd é um coletor de dados completo para construir pipelines de logging complexos e confiáveis em servidores. O Fluent Bit é um encaminhador mais leve e rápido projetado para coleta na borda, como em dispositivos IoT ou dentro de containers individuais. Eles são complementares: o Fluent Bit pode encaminhar dados para o Fluentd para agregação e processamento. Para DevOps no Kubernetes, o Fluent Bit é frequentemente usado como um daemonset em nós, encaminhando para uma instância Fluentd centralizada.
O Fluentd é bom para engenheiros de DevOps?
Absolutamente. O Fluentd é considerado uma ferramenta fundamental no kit de ferramentas DevOps. Ele aborda diretamente a necessidade de DevOps por observabilidade abrangente, unificando logs entre desenvolvimento e operações. Permite depuração mais rápida, melhor monitoramento e tomada de decisão baseada em dados, que são fundamentais para a cultura DevOps. Sua integração com pipelines CI/CD, infraestrutura como código e orquestração de containers o torna uma opção perfeita para fluxos de trabalho DevOps modernos.
Conclusão
Para equipes DevOps que buscam dominar seus dados de observabilidade, o Fluentd não é apenas uma ferramenta — é uma fundação estratégica. Sua capacidade de criar uma camada de logging unificada, confiável e flexível a partir de fontes heterogêneas é incomparável no mundo open-source. Embora existam alternativas para nichos específicos, a maturidade, o extenso ecossistema de plugins e a escalabilidade comprovada do Fluentd o tornam a escolha padrão para pipelines sérios de agregação de logs. Se seu objetivo é construir uma plataforma de observabilidade robusta e independente de fornecedor que possa crescer com sua infraestrutura, começar com o Fluentd é uma das decisões arquitetônicas mais impactantes que você pode tomar.