Fluentd – El Recolector de Datos de Logs de Código Abierto Esencial para DevOps
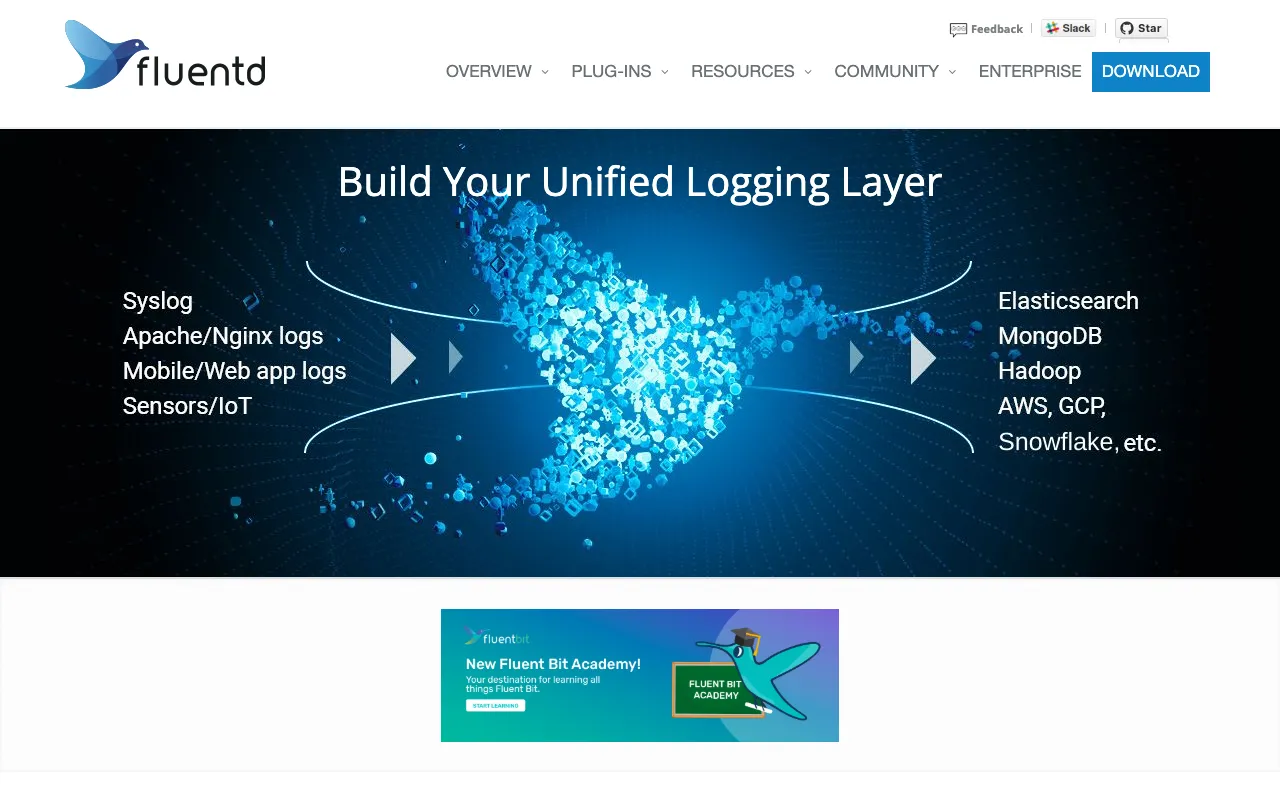
Fluentd es el recolector de datos de código abierto estándar de la industria que crea una capa de logging unificada para toda tu infraestructura DevOps. Resuelve el desafío crítico de la gestión de logs a gran escala al recopilar logs de cientos de fuentes de datos (aplicaciones, servidores, contenedores, bases de datos), procesarlos en tiempo real y enrutarlos de manera confiable a docenas de destinos como Elasticsearch, S3, Datadog o Slack. Como componente fundamental del panorama de la CNCF, Fluentd es confiado por empresas de todo el mundo para construir canalizaciones de observabilidad robustas y escalables que empoderan a los ingenieros con información accionable.
¿Qué es Fluentd?
Fluentd es un demonio de recolección de datos distribuido y de código abierto escrito en Ruby y C. Su propósito principal es actuar como una capa de logging unificada, desacoplando las fuentes de datos de los sistemas backend. Piensa en él como un 'enrutador de logs' que se sitúa entre tus aplicaciones/infraestructura y tus sistemas de análisis o almacenamiento. Estandariza los formatos de datos (a JSON), proporciona lógica de almacenamiento en búfer y reintentos para confiabilidad, y permite una transformación y filtrado de datos flexible. Este enfoque es fundamental para las prácticas modernas de DevOps como el logging centralizado, la monitorización y el análisis, permitiendo a los equipos obtener una visión holística de sus sistemas independientemente de la pila tecnológica subyacente.
Características Principales de Fluentd
Logging Unificado con JSON
Fluentd estructura todos los datos como JSON, proporcionando un formato común para procesar datos de logs en toda tu pila. Esta estandarización simplifica el análisis, filtrado y enriquecimiento, haciendo que los logs de fuentes dispares (Nginx, Docker, aplicaciones Java, logs del kernel) sean inmediatamente utilizables por las herramientas de análisis posteriores.
Arquitectura Enchufable
Su fortaleza reside en un vasto ecosistema de más de 500 plugins contribuidos por la comunidad. Los plugins de 'Entrada' recopilan datos de fuentes como syslog, HTTP, TCP o Docker. Los plugins de 'Filtro' analizan y transforman datos (por ejemplo, grep, record_transformer). Los plugins de 'Salida' enrutan datos a destinos como Elasticsearch, Amazon S3, Kafka o Slack. Esta extensibilidad hace que Fluentd sea adaptable a prácticamente cualquier entorno.
Confiabilidad Integrada
Fluentd maneja los fallos con elegancia mediante almacenamiento en búfer en memoria y basado en archivos para prevenir la pérdida de datos. Si un destino como Elasticsearch deja de estar disponible, Fluentd reintentará el envío de los datos, garantizando la integridad de los datos de logs, una característica crítica para sistemas en producción y auditorías.
Bajo Consumo de Recursos
El motor central está escrito en C con un envoltorio en Ruby para flexibilidad, resultando en un alto rendimiento con una pequeña huella de memoria (aproximadamente 30-40MB). Esto lo hace ideal para implementarlo como un contenedor sidecar en Kubernetes o como un demonio en máquinas virtuales.
¿Quién Debería Usar Fluentd?
Fluentd es indispensable para ingenieros DevOps, SREs y equipos de plataforma que gestionan infraestructura nativa de la nube o híbrida. Es perfecto para organizaciones que implementan o escalan su estrategia de observabilidad, especialmente aquellas que usan Kubernetes (donde a menudo se implementa como daemonsets de Fluent Bit o Fluentd), arquitecturas de microservicios o implementaciones multi-nube. Si estás lidiando con logs fragmentados, construyendo una canalización de datos para gestión de eventos e información de seguridad (SIEM), o necesitas una forma confiable de alimentar datos a un data lake o una plataforma de análisis en tiempo real, Fluentd es la capa fundamental que necesitas.
Precios y Nivel Gratuito de Fluentd
Fluentd es software 100% de código abierto bajo la licencia Apache 2.0. No hay costo para descargar, usar o implementar Fluentd, lo que lo convierte en una solución increíblemente rentable para la agregación de logs. Toda la funcionalidad central y el extenso ecosistema de plugins están disponibles gratuitamente. El soporte comercial y las distribuciones empresariales (como TD Agent) son ofrecidos por Treasure Data, el creador original, para organizaciones que requieren SLAs garantizados y servicios profesionales.
Casos de uso comunes
- Logging centralizado para entornos de contenedores Kubernetes y Docker
- Construcción de una canalización de análisis de logs para seguridad y cumplimiento (integración SIEM)
- Transmisión de logs en tiempo real a Apache Kafka para arquitecturas basadas en eventos
- Agregación de logs de aplicaciones desde microservicios para depuración y monitorización unificadas
Beneficios clave
- Elimina silos de datos al proporcionar una vista unificada para todos los datos de logs, reduciendo drásticamente el tiempo medio de resolución (MTTR) de incidentes.
- Reduce la complejidad y el costo operativo al reemplazar múltiples soluciones puntuales con un recolector de datos flexible y escalable.
- Protege tu infraestructura de logging a futuro con un estándar impulsado por la comunidad y neutral frente a proveedores, que se integra con cualquier herramienta.
Pros y contras
Pros
- Completamente gratuito y de código abierto con una comunidad masiva y activa.
- Extremadamente flexible y extensible gracias a un rico ecosistema de plugins.
- Probado a escala de petabytes en producción por grandes empresas.
- Nativo de la nube por diseño, con soporte de primera clase para Kubernetes y Docker.
- Proporciona entrega de datos confiable con mecanismos de almacenamiento en búfer y reintentos.
Contras
- La configuración puede ser compleja para casos de uso avanzados, requiriendo una curva de aprendizaje.
- El núcleo basado en Ruby puede tener un mayor uso de memoria en comparación con alternativas puras en C/C++ como Fluent Bit para recolección en el edge.
- Gestionar un clúster de alta disponibilidad de Fluentd requiere una planificación cuidadosa y conocimiento operativo.
Preguntas frecuentes
¿Es Fluentd gratuito?
Sí, Fluentd es completamente gratuito y de código abierto. Puedes descargarlo, implementarlo y usarlo en cualquier entorno, desde un solo servidor hasta un clúster empresarial global, sin ningún costo de licencia. El código fuente está disponible públicamente en GitHub bajo la licencia Apache 2.0.
¿Cuál es la diferencia entre Fluentd y Fluent Bit?
Fluentd es un recolector de datos completo para construir canalizaciones de logging complejas y confiables en servidores. Fluent Bit es un reenviador más ligero y rápido diseñado para la recolección en el edge, como en dispositivos IoT o dentro de contenedores individuales. Son complementarios: Fluent Bit puede reenviar datos a Fluentd para agregación y procesamiento. Para DevOps en Kubernetes, Fluent Bit se usa a menudo como un daemonset en los nodos, reenviando a una instancia centralizada de Fluentd.
¿Es Fluentd bueno para ingenieros DevOps?
Absolutamente. Fluentd se considera una herramienta fundamental en el conjunto de herramientas DevOps. Aborda directamente la necesidad de observabilidad integral de DevOps al unificar los logs en desarrollo y operaciones. Permite una depuración más rápida, una mejor monitorización y una toma de decisiones basada en datos, que son fundamentales para la cultura DevOps. Su integración con canalizaciones CI/CD, infraestructura como código y orquestación de contenedores lo convierte en una opción perfecta para los flujos de trabajo DevOps modernos.
Conclusión
Para los equipos DevOps que buscan dominar sus datos de observabilidad, Fluentd no es solo una herramienta, es una base estratégica. Su capacidad para crear una capa de logging unificada, confiable y flexible a partir de fuentes heterogéneas no tiene igual en el mundo del código abierto. Si bien existen alternativas para nichos específicos, la madurez, el extenso ecosistema de plugins y la escalabilidad probada de Fluentd lo convierten en la elección predeterminada para canalizaciones serias de agregación de logs. Si tu objetivo es construir una plataforma de observabilidad robusta y agnóstica a proveedores que pueda crecer con tu infraestructura, comenzar con Fluentd es una de las decisiones arquitectónicas más impactantes que puedes tomar.