Fluentd – Le collecteur de données de logs open source essentiel pour le DevOps
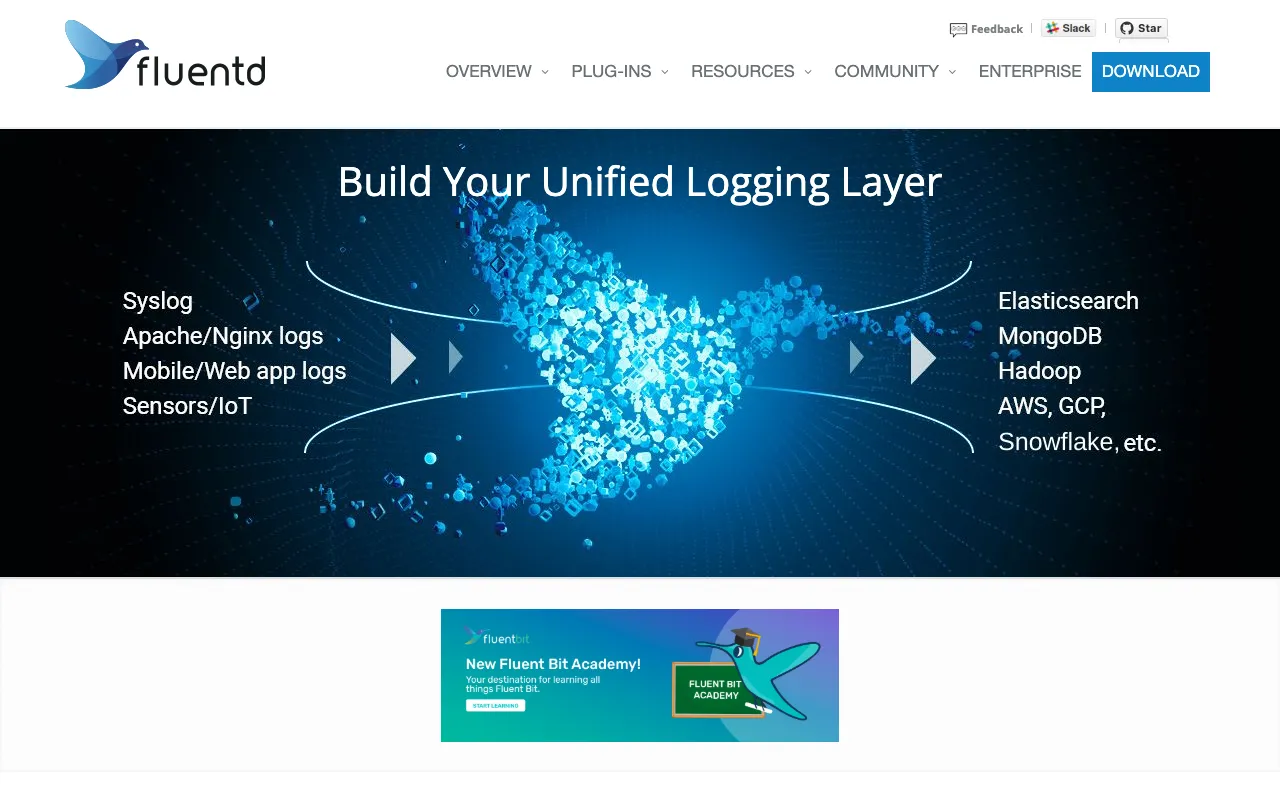
Fluentd est le collecteur de données open source standard de l'industrie qui crée une couche de journalisation unifiée pour toute votre infrastructure DevOps. Il résout le défi critique de la gestion des logs à grande échelle en collectant les logs de centaines de sources de données (applications, serveurs, conteneurs, bases de données), en les traitant en temps réel et en les routant de manière fiable vers des dizaines de destinations comme Elasticsearch, S3, Datadog ou Slack. En tant que composant central du paysage CNCF, Fluentd est utilisé par des entreprises du monde entier pour construire des pipelines d'observabilité robustes et évolutifs qui donnent aux ingénieurs des informations actionnables.
Qu'est-ce que Fluentd ?
Fluentd est un démon de collecte de données distribué et open source écrit en Ruby et C. Son objectif principal est d'agir comme une couche de journalisation unifiée, découplant les sources de données des systèmes backend. Considérez-le comme un 'routeur de logs' qui se place entre vos applications/infrastructures et vos systèmes d'analyse ou de stockage. Il standardise les formats de données (en JSON), fournit une logique de mise en mémoire tampon et de nouvelle tentative pour la fiabilité, et permet une transformation et un filtrage flexibles des données. Cette approche est fondamentale pour les pratiques DevOps modernes comme la journalisation centralisée, la surveillance et l'analyse, permettant aux équipes d'obtenir une vue holistique de leurs systèmes quelle que soit la pile technologique sous-jacente.
Fonctionnalités clés de Fluentd
Journalisation unifiée avec JSON
Fluentd structure toutes les données au format JSON, fournissant un format commun pour le traitement des données de logs dans toute votre pile. Cette standardisation simplifie l'analyse, le filtrage et l'enrichissement, rendant les logs de sources disparates (Nginx, Docker, applications Java, logs du noyau) immédiatement utilisables par les outils d'analyse en aval.
Architecture pluggable
Sa force réside dans un vaste écosystème de plus de 500 plugins contribués par la communauté. Les plugins 'Input' collectent les données de sources comme syslog, HTTP, TCP ou Docker. Les plugins 'Filter' analysent et transforment les données (par exemple, grep, record_transformer). Les plugins 'Output' routent les données vers des destinations comme Elasticsearch, Amazon S3, Kafka ou Slack. Cette extensibilité rend Fluentd adaptable à pratiquement n'importe quel environnement.
Fiabilité intégrée
Fluentd gère les pannes avec élégance grâce à une mise en mémoire tampon en mémoire et sur fichier pour éviter la perte de données. Si une destination comme Elasticsearch devient indisponible, Fluentd réessaiera d'envoyer les données, garantissant l'intégrité des données de logs – une fonctionnalité critique pour les systèmes de production et les pistes d'audit.
Faible empreinte ressources
Le moteur central est écrit en C avec un wrapper Ruby pour la flexibilité, ce qui donne des performances élevées avec une faible empreinte mémoire (environ 30-40 Mo). Cela le rend idéal pour un déploiement en tant que conteneur sidecar dans Kubernetes ou en tant que démon sur des machines virtuelles.
Qui devrait utiliser Fluentd ?
Fluentd est indispensable pour les ingénieurs DevOps, les SRE et les équipes plateforme gérant une infrastructure cloud-native ou hybride. Il est parfait pour les organisations mettant en œuvre ou faisant évoluer leur stratégie d'observabilité, en particulier celles utilisant Kubernetes (où il est souvent déployé sous forme de daemonsets Fluent Bit ou Fluentd), les architectures de microservices ou les déploiements multi-cloud. Si vous luttez avec des logs fragmentés, si vous construisez un pipeline de données pour la gestion des informations et événements de sécurité (SIEM), ou si vous avez besoin d'un moyen fiable d'alimenter un data lake ou une plateforme d'analyse en temps réel, Fluentd est la couche fondamentale dont vous avez besoin.
Tarification de Fluentd et version gratuite
Fluentd est un logiciel 100% open source sous licence Apache License 2.0. Il n'y a aucun coût pour télécharger, utiliser ou déployer Fluentd, ce qui en fait une solution d'agrégation de logs incroyablement rentable. L'ensemble des fonctionnalités centrales et le vaste écosystème de plugins sont librement disponibles. Un support commercial et des distributions entreprise (comme TD Agent) sont proposés par Treasure Data, le créateur original, pour les organisations nécessitant des SLA garantis et des services professionnels.
Cas d'utilisation courants
- Journalisation centralisée pour les environnements de conteneurs Kubernetes et Docker
- Construction d'un pipeline d'analyse de logs pour la sécurité et la conformité (intégration SIEM)
- Streaming de logs en temps réel vers Apache Kafka pour les architectures orientées événements
- Agrégation des logs d'application des microservices pour un débogage et une surveillance unifiés
Principaux avantages
- Élimine les silos de données en fournissant une vue unique pour toutes les données de logs, réduisant considérablement le temps moyen de résolution (MTTR) des incidents.
- Réduit la complexité opérationnelle et les coûts en remplaçant plusieurs solutions ponctuelles par un collecteur de données flexible et évolutif.
- Prépare l'avenir de votre infrastructure de journalisation avec une norme neutre vis-à-vis des fournisseurs, pilotée par la communauté, qui s'intègre à n'importe quel outil.
Avantages et inconvénients
Avantages
- Complètement gratuit et open source avec une communauté massive et active.
- Extrêmement flexible et extensible via un riche écosystème de plugins.
- Éprouvé à l'échelle du pétaoctet en production par des grandes entreprises.
- Cloud-native par conception, avec un support de première classe pour Kubernetes et Docker.
- Fournit une livraison de données fiable avec des mécanismes de mise en mémoire tampon et de nouvelle tentative.
Inconvénients
- La configuration peut être complexe pour les cas d'utilisation avancés, nécessitant une courbe d'apprentissage.
- Le cœur basé sur Ruby peut avoir une utilisation mémoire plus élevée par rapport aux alternatives purement C/C++ comme Fluent Bit pour la collecte en périphérie.
- La gestion d'un cluster Fluentd à haute disponibilité nécessite une planification minutieuse et des connaissances opérationnelles.
Foire aux questions
Fluentd est-il gratuit ?
Oui, Fluentd est complètement gratuit et open source. Vous pouvez le télécharger, le déployer et l'utiliser dans n'importe quel environnement – d'un seul serveur à un cluster d'entreprise mondial – sans aucun frais de licence. Le code source est disponible publiquement sur GitHub sous licence Apache 2.0.
Quelle est la différence entre Fluentd et Fluent Bit ?
Fluentd est un collecteur de données complet pour construire des pipelines de journalisation complexes et fiables sur les serveurs. Fluent Bit est un forwarder plus léger et plus rapide conçu pour la collecte en périphérie, par exemple sur des appareils IoT ou dans des conteneurs individuels. Ils sont complémentaires : Fluent Bit peut transmettre des données à Fluentd pour l'agrégation et le traitement. Pour le DevOps sur Kubernetes, Fluent Bit est souvent utilisé comme daemonset sur les nœuds, transmettant à une instance Fluentd centralisée.
Fluentd est-il adapté aux ingénieurs DevOps ?
Absolument. Fluentd est considéré comme un outil fondamental dans la boîte à outils DevOps. Il répond directement au besoin DevOps d'observabilité complète en unifiant les logs entre le développement et les opérations. Il permet un débogage plus rapide, une meilleure surveillance et une prise de décision basée sur les données, ce qui est au cœur de la culture DevOps. Son intégration avec les pipelines CI/CD, l'infrastructure as code et l'orchestration de conteneurs en fait un choix parfait pour les workflows DevOps modernes.
Conclusion
Pour les équipes DevOps cherchant à maîtriser leurs données d'observabilité, Fluentd n'est pas seulement un outil – c'est une fondation stratégique. Sa capacité à créer une couche de journalisation unifiée, fiable et flexible à partir de sources hétérogènes est inégalée dans le monde open source. Bien que des alternatives existent pour des niches spécifiques, la maturité de Fluentd, son vaste écosystème de plugins et sa scalabilité éprouvée en font le choix par défaut pour les pipelines d'agrégation de logs sérieux. Si votre objectif est de construire une plateforme d'observabilité robuste et agnostique vis-à-vis des fournisseurs qui peut évoluer avec votre infrastructure, commencer avec Fluentd est l'une des décisions architecturales les plus impactantes que vous puissiez prendre.